> ## Documentation Index
> Fetch the complete documentation index at: https://docs.unstructured.io/llms.txt
> Use this file to discover all available pages before exploring further.
# VectorShift
[VectorShift](https://vectorshift.ai/) is an integrated framework of no-code, low-code, and out of the box generative AI solutions
to build AI search engines, assistants, chatbots, and automations.
VectorShift's platform allows you to design, prototype, build, deploy,
and manage generative AI workflows and automation across two interfaces: no-code and code SDK.
This hands-on demonstration uses the no-code interface to walk you through creating a VectorShift pipeline project. This project
enables you to use GPT-4o-mini to chat in real time with a PDF document that is processed by Unstructured and has its processed data stored in a
[Pinecone](https://www.pinecone.io/) vector database.
## Prerequisites
* A Pinecone account. [Get an account](https://app.pinecone.io/).
* A Pinecone API key in your Pinecone account. To create an API key, do the following:
1. [Sign in to your Pinecone account and open the API keys page](https://app.pinecone.io/organizations/-/projects/-/keys).
2. Click **+ API key**.
3. For **API key name**, enter some descriptive name for the API key.
4. Click **Create key**.
5. Copy the generated API key to some secure location. You will not be able to access this API key again after you close the dialog.
* A Pinecone serverless index in your Pinecone account.
Creating a serverless index on your own is optional.
An index is not required to exist in advance.
When you set up the connector, at runtime, the index behavior is as follows:
For the [Unstructured Pipelines](/pipelines/overview) and [Unstructured API](/api-reference/overview):
* Your workflow must contain an embedder node, and the embedder node must specify the embedding model that Unstructured will use to generate the embeedings.
* If an existing index name is specified,
and the number of dimensions that Unstructured generates does not match the number of dimensions that are specified in the existing index's embedding settings, the run will fail.
You must change the number of dimensions in your workflow's embedder node or your existing index's embedding settings to match, and try the run again.
* If an index name is not specified, Unstructured creates a new index in your Pinecone account. The
new index's name will be `u--`.
For [Unstructured Ingest](/open-source/ingestion/overview):
* If an existing index name is specified, and Unstructured generates embeddings,
but the number of dimensions that are generated does not match the existing index's embedding settings, the run will fail.
You must change your Unstructured embedding settings or your existing index's embedding settings to match, and try the run again.
* If an index name is not specified, Unstructured creates a new index in your Pinecone account. The new index's name will be `unstructuredautocreated`.
If you create a new index or use an existing one, Unstructured recommends that all records in the target index have a field
named `record_id` with a string data type.
Unstructured can use this field to do intelligent document overwrites. Without this field, duplicate documents
might be written to the index or, in some cases, the operation could fail altogether.
To create a serverless index on your own, do the following:
1. [Sign in to your Pinecone account and open the Create a new index page](https://app.pinecone.io/organizations/-/projects/-/create-index/serverless).
2. For **Enter index name**, enter some descriptive name for the index.
3. For **Configuration**, select the check box labelled **Custom settings**, or click the tile labelled **Manual configuration**.
Do not click any of the other tiles, such as **text-embedding-3-large**. Clicking any of these other tiles will cause Pinecone to generate embeddings instead of
having Unstructured generate them. If Pinecone generates embeddings instead of Unstructured, this could cause any related Unstructured workflows to fail.
4. For **Vector type**, select **Dense**.
5. For **Dimension**, enter the number of dimensions for the embeddings that Unstructured will generate.
The number of dimensions that you enter here must match the number of dimensions for the embedding model that you use in any related Unstructured workflows or ingestion pipelines. If these numbers do not
match in both places, this could cause any related Unstructured workflows or ingestion pipelines to fail.
6. For **Metric**, select **cosine**.
7. Leave **Capacity mode** set to **Serverless**.
8. You can leave **Cloud provider** and **Region** set to their default values, or you can select a cloud provider and region that is closest to you, if available.
9. Click **Create index**.
* Within a Pinecone serverless index, custom [namespaces](https://docs.pinecone.io/guides/index-data/indexing-overview#namespaces) are supported but are not required.
Also:
* [Sign up for an OpenAI account](https://platform.openai.com/signup), and [get your OpenAI API key](https://help.openai.com/en/articles/4936850-where-do-i-find-my-openai-api-key).
* [Sign up for a VectorShift Starter account](https://app.vectorshift.ai/api/signup).
* If you do not already have an Unstructured account, sign up for one:
1. If you do not already have an Unstructured account, [sign up for free](https://unstructured.io/?modal=try-for-free).
After you sign up, you are automatically signed in to your new Unstructured **Let's Go** account, at [https://platform.unstructured.io](https://platform.unstructured.io).
To sign up for a **Business** account instead, [contact Unstructured Sales](https://unstructured.io/?modal=contact-sales), or [learn more](/api-reference/overview#pricing).
2. If you have an Unstructured **Let's Go**, **Pay-As-You-Go**, or **Business SaaS** account and are not already signed in, sign in to your account at [https://platform.unstructured.io](https://platform.unstructured.io).
For other types of **Business** accounts, see your Unstructured account administrator for sign-in instructions,
or email Unstructured Support at [support@unstructured.io](mailto:support@unstructured.io).
3. Get your Unstructured API key:
a. After you sign in to your Unstructured **Let's Go**, **Pay-As-You-Go**, or **Business** account, click **API Keys** on the sidebar.
For a **Business** account, before you click **API Keys**, make sure you have selected the organizational workspace you want to create an API key
for. Each API key works with one and only one organizational workspace. [Learn more](/pipelines/account/workspaces#create-an-api-key-for-a-workspace).
b. Click **Generate API Key**.
c. Follow the on-screen instructions to finish generating the key.
d. Click the **Copy** icon next to your new key to add the key to your system's clipboard. If you lose this key, simply return and click the **Copy** icon again.
## Create and run the demonstration project
Although you can use any [supported file type](/pipelines/supported-file-types) or data in any
[supported source type](/pipelines/sources/overview) for the input into Pinecone, this demonstration uses [the text of the United States Constitution in PDF format](https://constitutioncenter.org/media/files/constitution.pdf).
1. If you are not already signed in, sign in to your Unstructured account.
2. [Create a source connector](/pipelines/sources/overview), if you do not already have one, to connect Unstructured to the source location where the PDF file is stored.
3. [Create a Pinecone destination connector](/pipelines/destinations/pinecone), if you do not already have one, to connect Unstructured to your Pinecone serverless index.
4. [Create a workflow](/pipelines/workflows#create-a-workflow) that references this source connector and destination connector.
5. [Run the workflow](/pipelines/workflows#edit-delete-or-run-a-workflow).
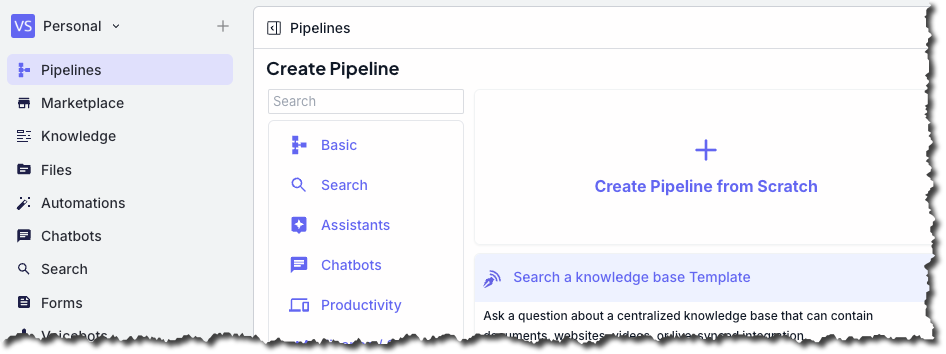
1. Sign in to your VectorShift account dashboard.
2. On the sidebar, click **Pipelines**.
3. Click **New**.
4. Click **Create Pipeline from Scratch**.
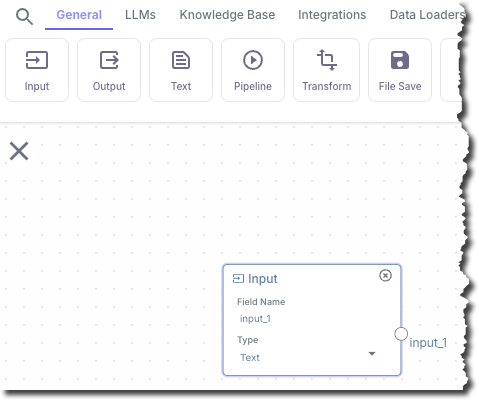
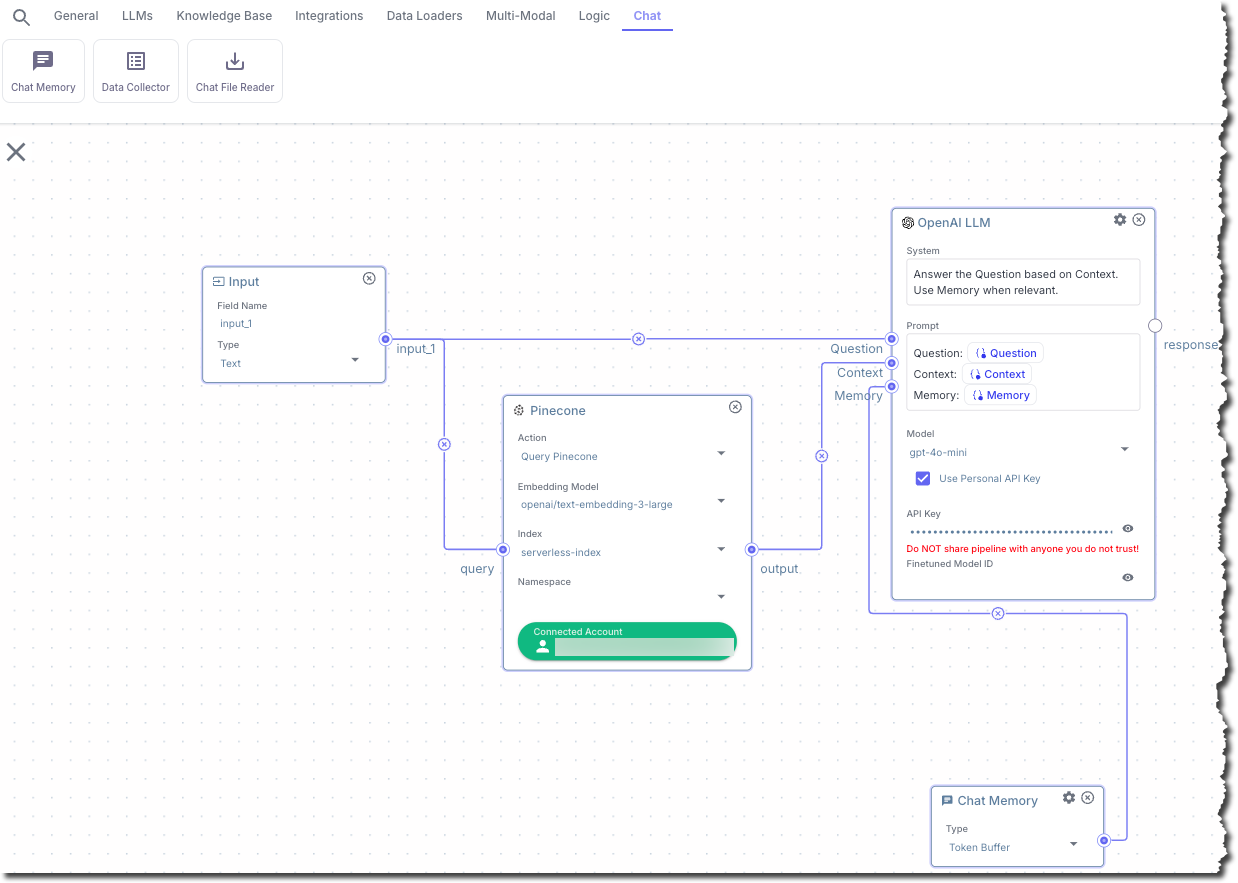
In this step, you add a node to the pipeline. This node takes user-supplied chat messages and sends them as input to Pinecone, and as input to a text-based LLM, for contextual searching.
In the top pipeline node chooser bar, on the **General** tab, click **Input**.
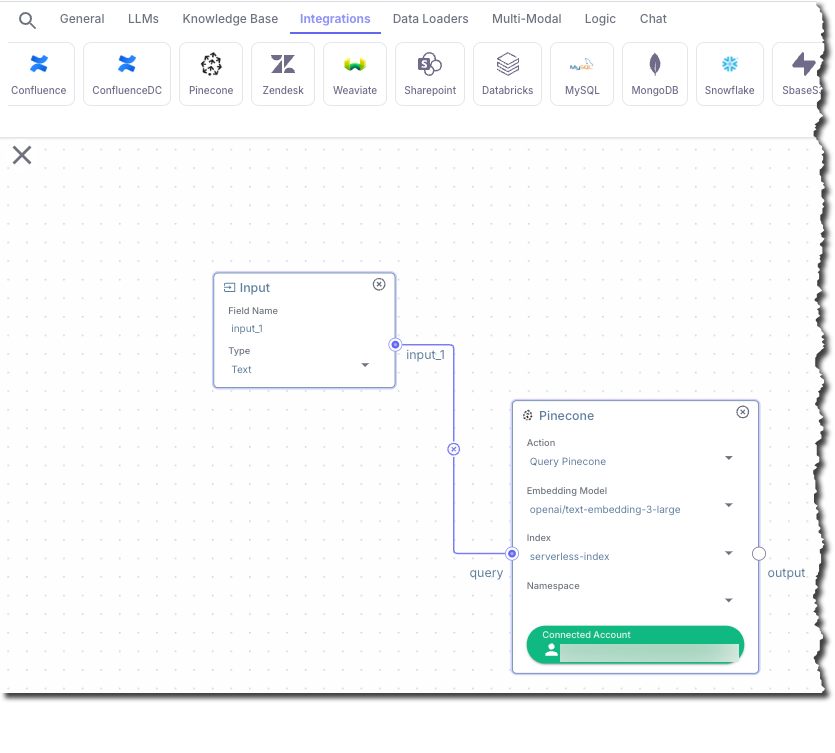
In this step, you add a node that connects to the Pinecone serverless index.
1. In the top pipeline node chooser bar, on the **Integrations** tab, click **Pinecone**.
2. In the **Pinecone** node, for **Embedding Model**, select **openai/text-embedding-3-large**.
3. Click **Connected Account**.
4. In the **Select Pinecone Account** dialog, click **Connect New**.
5. Enter the **API Key** and **Region** for your Pinecone serverless index, and then click **Save**.
6. For **Index**, selet the name of your Pinecone serverless index.
7. Connect the **input\_1** output from the **Input** node to the **query** input in the **Pinecone** node.
To make the connection, click and hold your mouse pointer inside of the circle next to **input\_1** in the **Input** node.
While holding your mouse pointer, drag it over into the circle next to **query** in the **Pinecone** node. Then
release your mouse pointer. A line appears between these two circles.
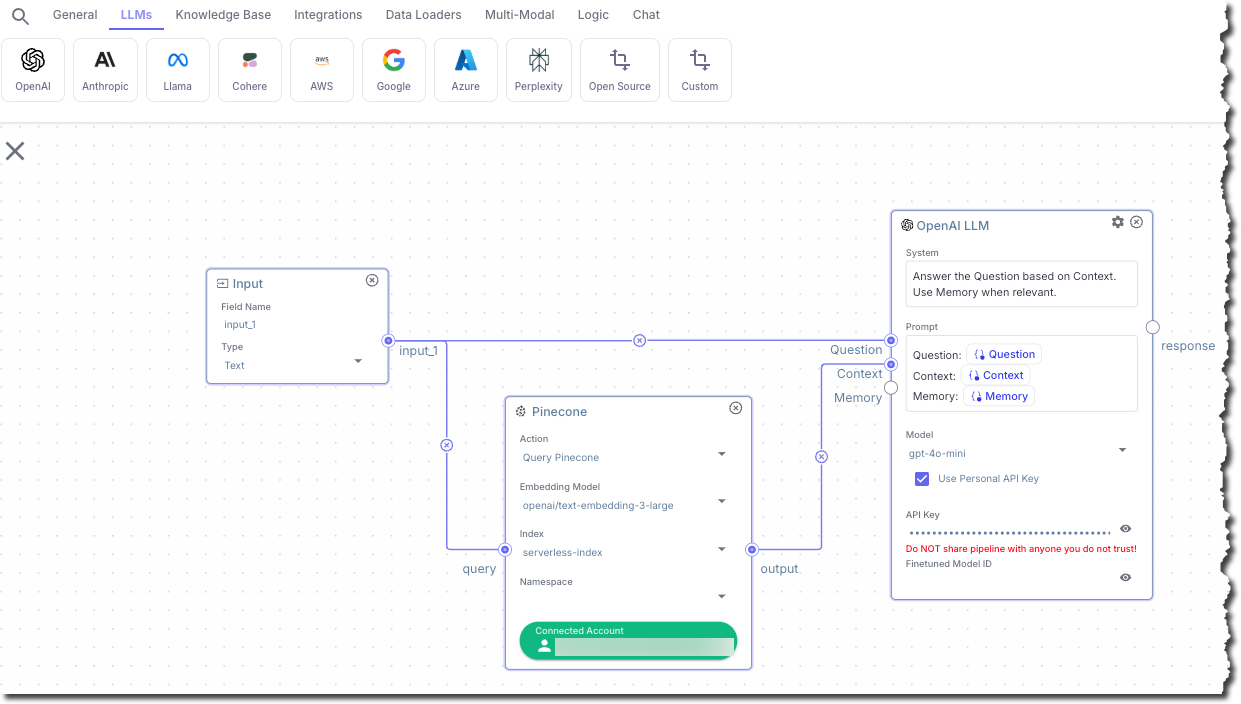
In this step, you add a node that builds a prompt and then sends it to a text-based LLM.
1. In the top pipeline node chooser bar, on the **LLMs** tab, click **OpenAI**.
2. In the **OpenAI LLM** node, for **System**, enter the following text:
```
Answer the Question based on Context. Use Memory when relevant.
```
To answer the question, the preceding prompt uses the context along with general information that the text-based LLM is
trained on. To use only the context to answer the question, you can change the prompt, for example to something like this:
```text theme={null}
Answer the Question based only on the Context. Do not use any other sources of
information. If the context does not provide enough information to answer the
question, reply with 'I do not have enough context to answer the question.'
Use Memory when relevant.
```
3. For **Prompt**, enter the following text:
```
Question: {{Question}}
Context: {{Context}}
Memory: {{Memory}}
```
4. For **Model**, select **gpt-4o-mini**.
5. Check the box titled **Use Personal API Key**.
6. For **API Key**, enter your OpenAI API key.
7. Connect the **input\_1** output from the **Input** node to the **Question** input in the **OpenAI LLM** node.
8. Connect the **output** output from the **Pinecone** node to the **Context** input in the **OpenAI LLM** node.
In this step, you add a node that adds chat memory to the session.
1. In the top pipeline node chooser bar, on the **Chat** tab, click **Chat Memory**.
2. Connect the output from the **Chat Memory** node to the **Memory** input in the **OpenAI LLM** node.
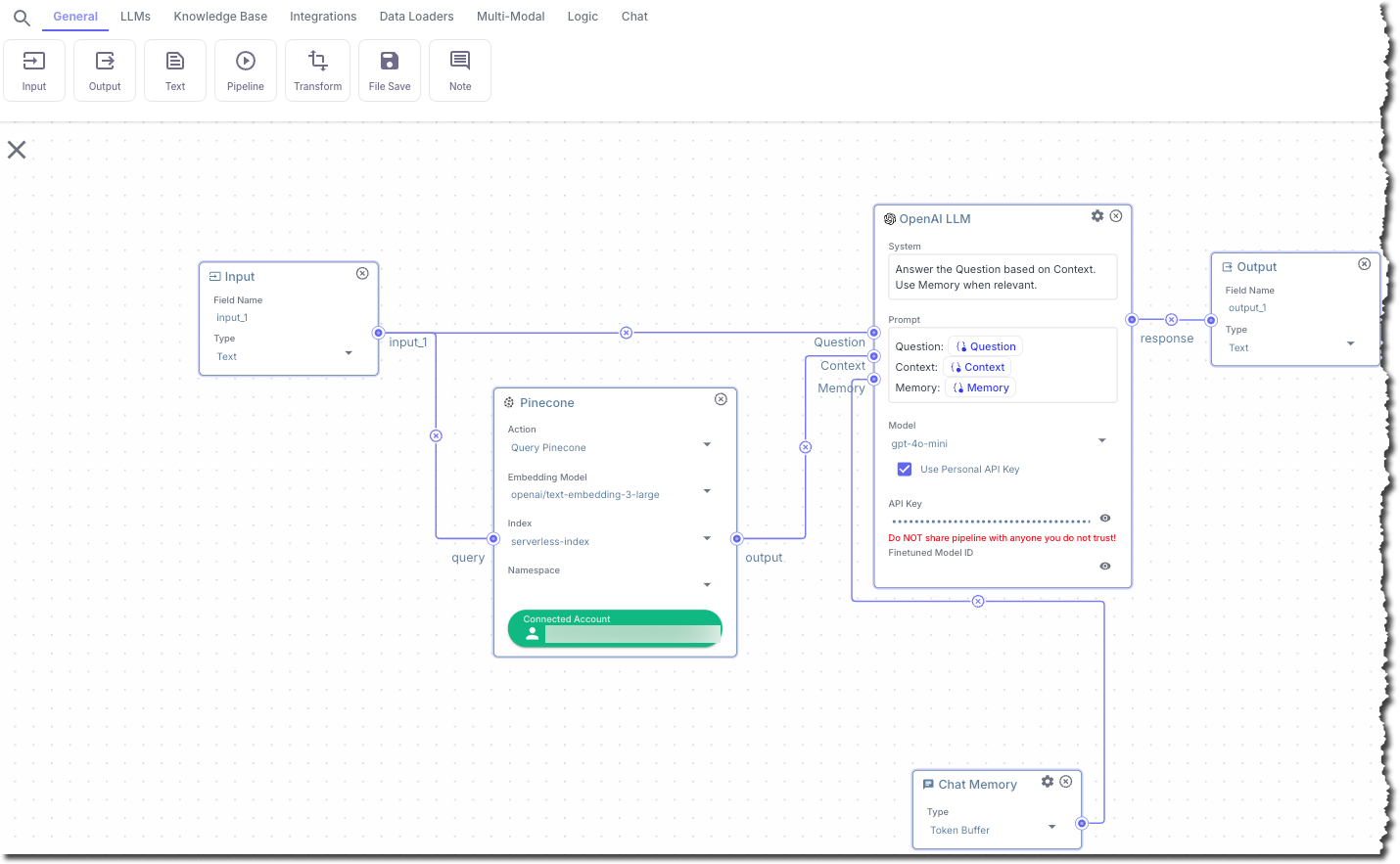
In this step, you add a node that displays the chat output.
1. In the top pipeline node chooser bar, on the **General** tab, click **Output**.
2. Connect the **response** output from the **OpenAI LLM** node to the input in the **Output** node.
1. In the upper corner of the pipeline designer, click the play (**Run Pipeline**) button.
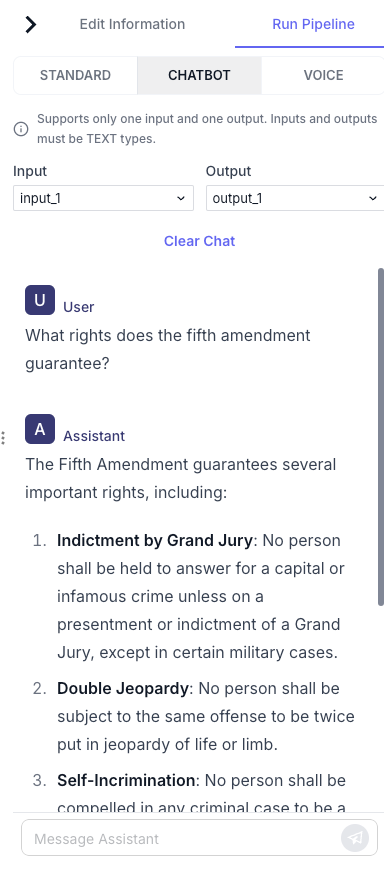
2. In the chat pane, on the **Chatbot** tab, enter a question into the **Message Assistant** box, for example, `What rights does the fifth amendment guarantee?` Then press the send button.
3. Wait until the answer appears.
4. Ask as many additional questions as you want to.
## Learn more
See the [VectorShift documentation](https://docs.vectorshift.ai/).
 2. In the chat pane, on the **Chatbot** tab, enter a question into the **Message Assistant** box, for example, `What rights does the fifth amendment guarantee?` Then press the send button.
2. In the chat pane, on the **Chatbot** tab, enter a question into the **Message Assistant** box, for example, `What rights does the fifth amendment guarantee?` Then press the send button.
 3. Wait until the answer appears.
4. Ask as many additional questions as you want to.
3. Wait until the answer appears.
4. Ask as many additional questions as you want to.