Documentation Index
Fetch the complete documentation index at: https://docs.unstructured.io/llms.txt
Use this file to discover all available pages before exploring further.
For the Unstructured open source library version of this page, see Chunking for open source.
After partitioning, chunking rearranges the resulting document elements into manageable “chunks” to stay within
the limits of an embedding model and to improve retrieval precision. The goal is to retrieve only parts of documents
that contain only the information that is relevant to a user’s query. You can specify if and how Unstructured chunks
those elements, based on your intended end use.
During chunking, Unstructured uses a basic chunking strategy that attempts to combine two or more consecutive text elements
into each chunk that fits together within the max characters setting. To determine the best max characters setting, see the documentation
for the embedding model that you want to use.
You can further control this behavior with by title, by page, and by similarity chunking strategies.
In all cases, Unstructured will only split individual elements if they exceed the specified max characters length.
After chunking, you will have document elements of only the following types:
CompositeElement: Any text element will become aCompositeElementafter chunking. A composite element can be a combination of two or more original text elements that together fit within the max characters setting. It can also be a single element that doesn’t leave room in the chunk for any others but fits by itself. Or it can be a fragment of an original text element that was too big to fit in one chunk and required splitting.Table: A table element is not combined with other elements, and if it fits within the max characters setting it will remain as is.TableChunk: Large tables that exceed the max characters setting are split into specialTableChunkelements.
orig_elements field is added to the metadata field of each chunked element.
The orig_elements field is a list of the original elements that were used to create the current chunked element. This list is output in
gzip compressed, Base64-encoded format. To get back to the original content for this list, Base64-decode the list’s bytes, and then gzip decompress them as UTF-8.
Learn how.
After chunking, Image elements are not preserved in the output. However,
if High Res partitioning is used and the option to include original elements is also specified, the orig_elements field of each chunked element will contain
an image_base64 field for each detected image and table associated with the original elements listed within orig_elements. To get back to the
original content for an image_base64 field, Base64-decode the field’s bytes.
Learn how.
The following sections provide information about the available chunking strategies and their settings.
You can change a workflow’s preconfigured strategy only through Custom workflow settings.
Basic chunking strategy
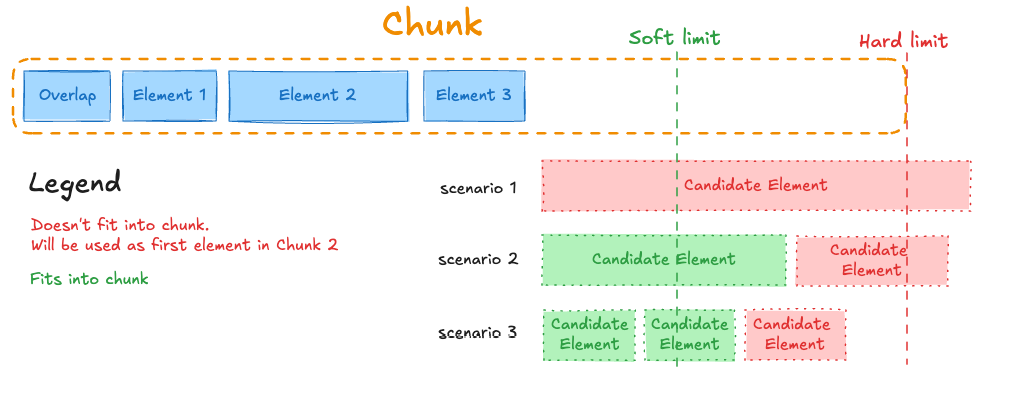
The basic chunking strategy uses only the max characters setting (an absolute or “hard” limit) and new after n characters setting (an approximate or “soft” limit) to combine sequential elements to maximally fill each chunk. This strategy adds elements to a chunk until the new after n characters limit is reached. A new chunk is then started. No chunk will exceed the max characters limit. For elements larger than the “max characters” limit, the text is split into multiple chunks at spaces or new lines to avoid cutting words. Table elements are always treated as standalone chunks. If a table is too large, the table is chunked by rows. This strategy does not use section boundaries, page boundaries, or content similarities to determine the chunks’ contents. The following diagram illustrates conceptually how a candidate element is chunked to fit within the max characters (hard) and new after n characters (soft) limits.- In scenario 1, the candidate element exceeds the hard limit, and so the candidate element will become the first element in the next chunk.
- In scenario 2, the first candidate element exceeds the soft limit but remains within the hard limit. Because the second candidate element begins after the soft limit has been reached, the second candidate element will become the first element in the next chunk.
- In scenario 3, the first two candidate elements exceed the soft limit but remain within the hard limit. Even though the third candidate element remains within the hard limit, because it begins after the soft limit has been reached, the third candidate element will become the first element in the next chunk.

Chunk by title strategy
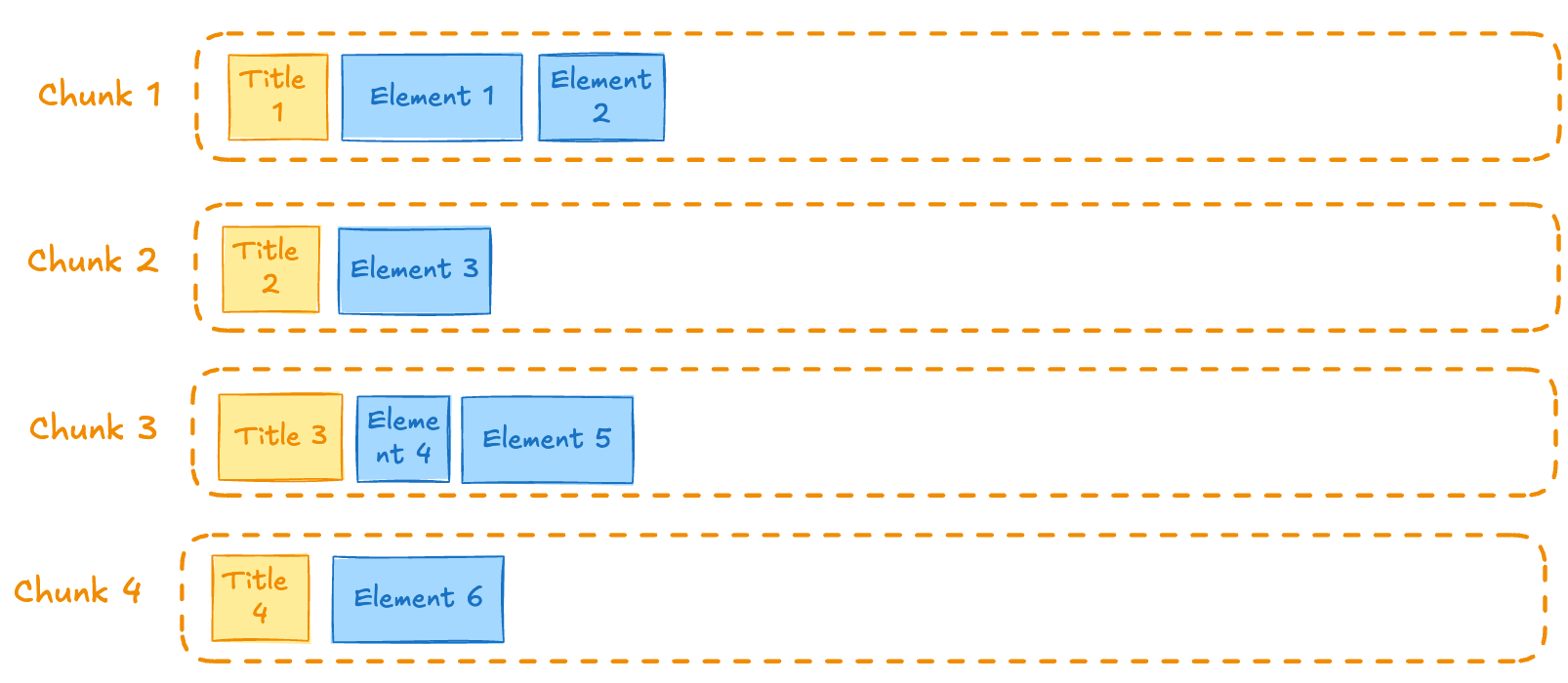
The by-title chunking strategy attempts to preserve section boundaries when determining the chunks’ contents, primarily when a Title element is encountered. The title is used as the section header for the chunk. The max characters and new after n characters settings are still respected. The following conceptual diagram illustrates conceptually how elements are chunked when Title elements are encountered (see Chunks 1, 4, and 6), while still respecting the max characters and new after n characters settings (see Chunks 2 and 3):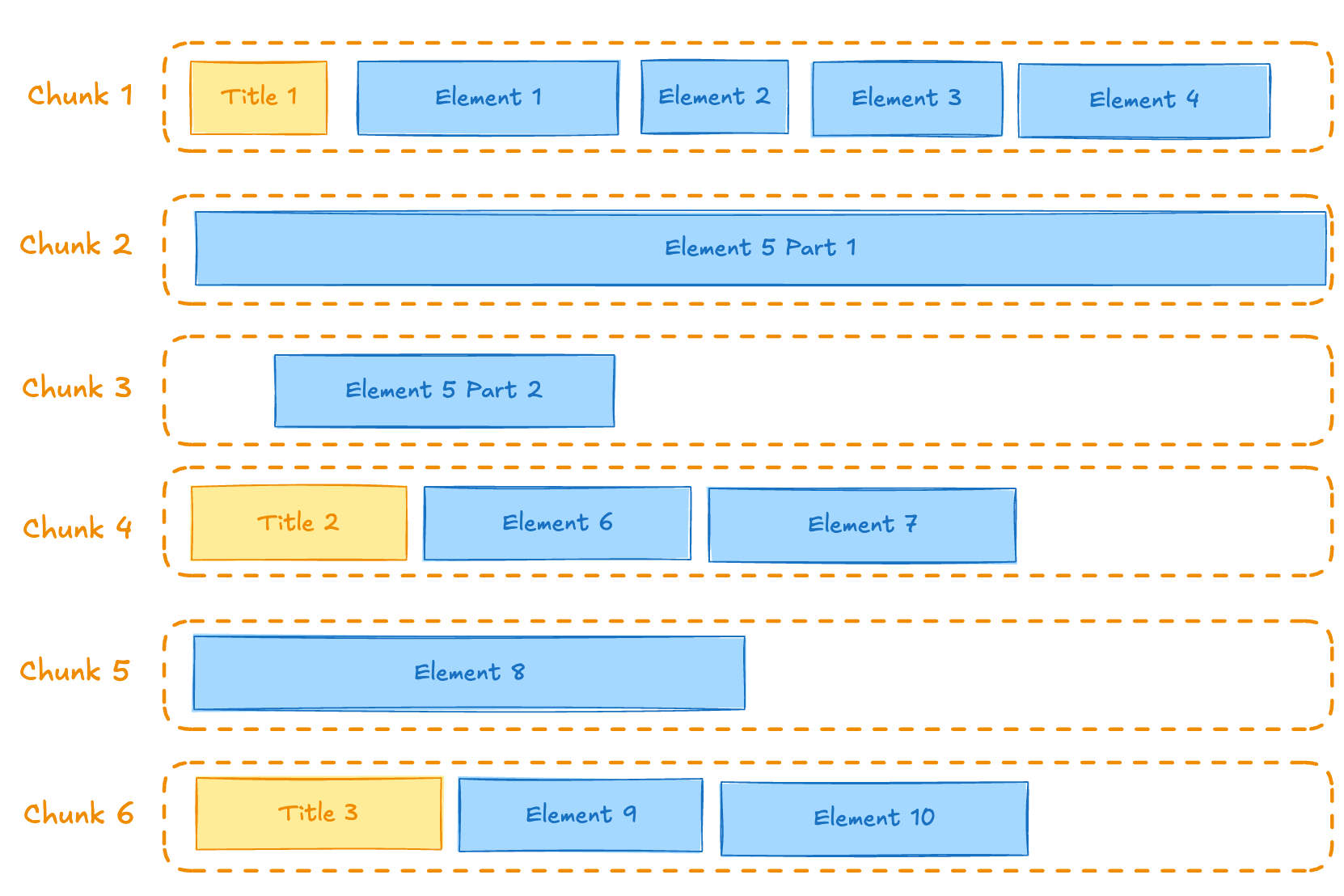

Chunk by page strategy
The by-page chunking strategy attempts to preserve page boundaries when determining the chunks’ contents. A single chunk should not contain text that occurred in two different page. When a new page starts, the existing chunk is closed and a new one is started, even if the next element would fit in the prior chunk. The following diagram shows how a chunk by page strategy with a max characters setting of 200 would chunk the following text. Notice that due to the page break, the second chunk is very small, as it could not fit into the first chunk’s hard character limit.Nonetheless, the second chunk is still part of same page as the first chunk:

Chunk by similarity strategy
The by-similarity chunking strategy uses the sentence-transformers/multi-qa-mpnet-base-dot-v1 embedding model to identify topically similar sequential elements and combines them into chunks. As with the other chunking strategies, chunks will never exceed the absolute maximum chunk size set by Max characters. For this reason, not all elements that share a topic will necessarily appear in the same chunk. However, with this strategy you can guarantee that two elements with low similarity will not be combined in a single chunk. To use this chunking strategy, specify Chunk by similarity for a Chunker node in a workflow. You can control the level of topic similarity you require for elements to have by setting Similarity threshold. The following diagram shows how a chunk by similarity strategy with a max characters setting of 1000 and similarity threshold of 0.5 would chunk the following text. Notice that the two chunks are well short of the 1000-character hard limit, as the paragraph break introduces a convenient lexical construct for helping determinine the similarities of sentences to each other:
Max characters setting
Specifies the absolute maximum number of characters in a chunk. To specify this setting, specify a number for Max characters. This setting applies to all of the chunking strategies.Combine text under n characters setting
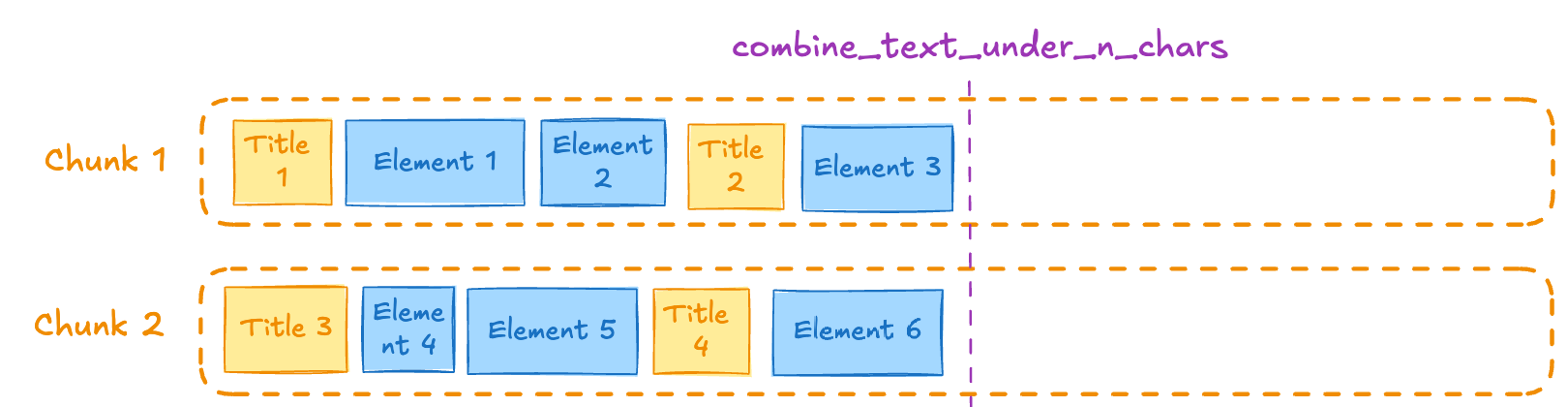
Combines elements from a section into a chunk until a section reaches a length of this many characters. To specify this setting, specify a number for Combine text under n chars. This setting applies only to the chunking strategy Chunk by title.Include original elements setting
If Include original elements is enabled, the elements that were used to form a chunk appear in themetadata field’s orig_elements field for that chunk.
This setting applies to all of the chunking strategies.
Multipage sections setting
If Multipage sections is enabled, this allows sections to span multiple pages. This setting applies only to the chunking strategy Chunk by title.New after n characters setting
Closes new sections after reaching a length of this many characters. This is an approximate limit. To specify this setting, specify a number for New after n characters. This setting applies only to the chunking strategies Chunk by character, Chunk by title, and Chunk by page.Overlap setting
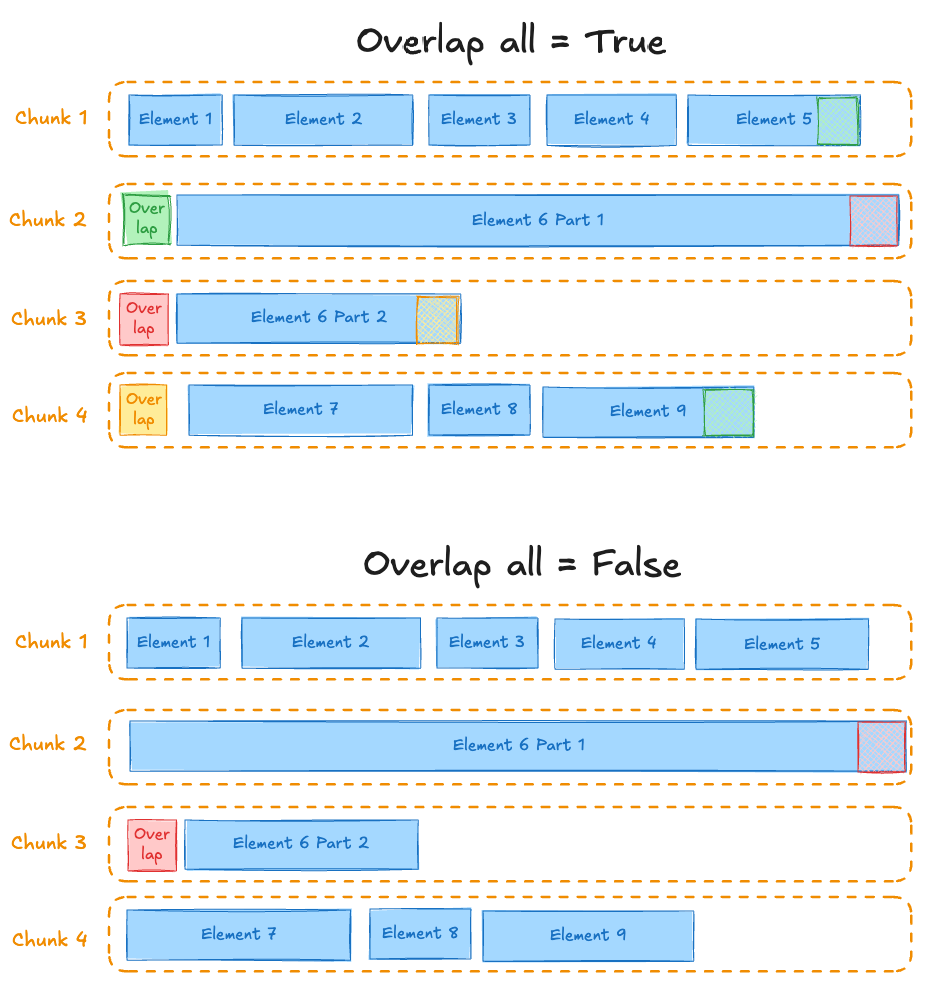
Applies a prefix of this many trailing characters from the prior text-split chunk to second and later chunks formed from oversized elements by text-splitting. To specify this setting, specify a number for Overlap . This setting applies only to the chunking strategies Chunk by character, Chunk by title, and Chunk by page.Overlap all setting
If Overlap all box is enabled, applies overlap to “normal” chunks formed by combining whole elements. Use with caution as this can introduce noise into otherwise clean semantic units. This setting applies only to the chunking strategies Chunk by character, Chunk by title, and Chunk by page.Similarity threshold setting
Specifies the minimum similarity that text in consecutive elements must have to be included in the same chunk. This must be a value between0.0 and 1.0, exclusive (0.01 to 0.99). The default is 0.5 if not otherwise specified.
To specify this setting, specify a number for Similarity threshold.
This setting applies only to the chunking strategy Chunk by similarity.
Contextual chunking
A technique known as contextual chunking prepends chunk-specific explanatory context to each chunk. Contextual chunking has been shown to enhance traditional RAG solutions by yielding significant improvements in retrieval accuracy, which directly translates to better performance in downstream tasks. Contextual retrieval overview from Anthropic. To apply contextual chunking, enable Contextual chunking in the settings for any chunking strategy. This chunk-specific explanatory context information is typically a couple of sentences in length. Contextual chunking happens before any embeddings are generated. When contextual chunking is applied, the contextual information in each chunk begins withPrefix: and ends with a semicolon (;).
The chunk’s original content begins with Original:.
For example, without contextual chunking applied, elements would for instance be generated similar to the following.
Line breaks have been inserted here for readability. The output will not contain these line breaks:
Implementing chunking
To have Unstructured perform chunking, do the following:- For Unstructured UI users, add a Chunker node to an Unstructured custom workflow.
- For Unstructured API users, add a Chunker node
as either as an object in a
workflow_nodesarray (for curl) or as aWorkflowNodein aWorkflowNodescollection (for Python) whenever you create a workflow, update a workflow, or create an on-demand workflow job.
Learn more
- “Breaking It Down: Chunking Strategies” in Level Up Your GenAI Apps: Essential Data Preprocessing for Any RAG System
- Contextual Chunking in Unstructured Platform: Boost Your RAG Retrieval Accuracy
- Chunking for RAG: best practices.