What is Unstructured Pipelines?
Unstructured Pipelines is a no-code user interface, pay-as-you-go platform for transforming your unstructured data into data that is ready for retrieval-augmented generation (RAG).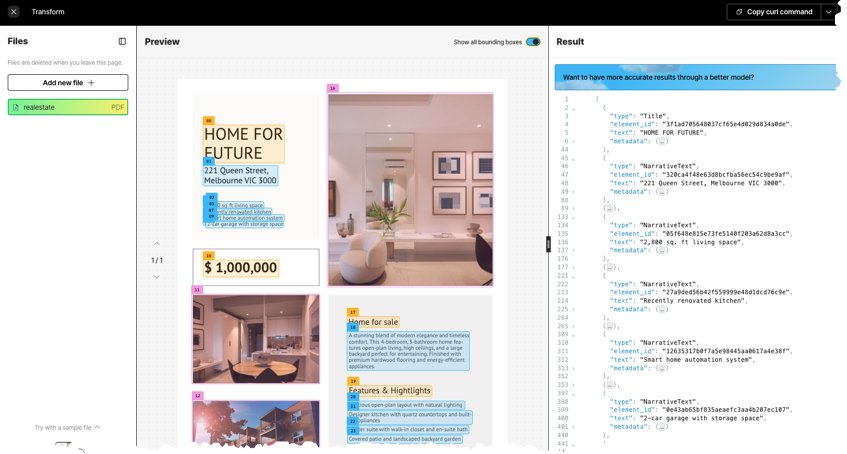
An example of Unstructured Pipelines, showing a local file being partitioned
Read the announcement.
How does it work?
To get your data RAG-ready, Unstructured moves it through the following process:1
Connect
Unstructured offers multiple source connectors to connect to your data in its existing location.
2
Route
Routing determines which strategy Unstructured uses to transform your documents into Unstructured’s canonical JSON schema. Unstructured provides four partitioning strategies for document transformation, as follows.Unstructured recommends that you choose the Auto partitioning strategy in most cases. With Auto, Unstructured does all
the heavy lifting, optimizing at runtime for the highest quality at the lowest cost page-by-page.You should consider the following additional strategies only if you are absolutely sure that your documents are of the same
type. Each of the following strategies are best suited for specific situations. Choosing one of these
strategies other than Auto for sets of documents of different types could produce undesirable results,
including reduction in transformation quality.
- VLM: For the highest-quality transformation of these file types:
.bmp,.gif,.heic,.jpeg,.jpg,.pdf,.png,.tiff, and.webp. - High Res: For all other supported file types, and for the generation of bounding box coordinates.
- Fast: For text-only documents.
.pdf files, the Auto partitioning strategy routes these files’ pages
on a page-by-page basis, as follows:- A page is routed to Fast when it contains only embedded text and no images or tables are detected.
- All other kinds of pages are routed to VLM or High Res, depending on the complexity of a page’s content. Unstructured constantly optimizes its proprietary algorithm for routing to VLM or High Res in these cases.
3
Transform
Your source document is transformed into Unstructured’s canonical JSON schema. Regardless of the input document, this JSON schema gives you a standardized output. It contains more than 20 elements, such as
Header, Footer, Title, NarrativeText, Table, Image, and many more. Each document is wrapped in extensive metadata so you can understand languages, file types, sources, hierarchies, and much more.4
Chunk
Unstructured provides these chunking strategies:
- Basic combines sequential elements up to specified size limits. Oversized elements are split, while tables are isolated and divided if necessary. Overlap between chunks is optional.
- By Title uses semantic chunking, understands the layout of the document, and makes intelligent splits.
- By Page attempts to preserve page boundaries when determining the chunks’ contents.
- By Similarity uses an embedding model to identify topically similar sequential elements and combines them into chunks.
5
Enrich
Images and tables can be optionally summarized. This generates enriched content around the images or tables that were parsed during the transformation process.
6
Embed
Unstructured uses optional third-party embedding providers such as OpenAI.
7
Persist
Unstructured offers multiple destination connectors, including all major vector databases.
1
Source Connectors
Source connectors to ingest your data into Unstructured for transformation.
2
Destination Connectors
Destination connectors tell Unstructured where to write your transformed data to.
3
Workflow
A workflow connects sources to destinations and provide chunking, embedding, and scheduling options.
4
Jobs
Jobs enable you to monitor data transformation progress.
What support is there for compliance?
The platform is designed to comply with SOC 2 Type 1, SOC 2 Type 2, HIPAA, GDPR, ISO 27001, FedRAMP, and CMMC 2.0 Level 2. It has support for over 50 languages. For details, see the Unstructured Trust Portal.How am I billed?
To use Unstructured Pipelines, you must have an Unstructured account for billing purposes. Unstructured offers different account types with different pricing plans:- Let’s Go and Pay-As-You-Go - A single user, with a single workspace, hosted alongside other accounts on Unstructured’s cloud infrastructure.
-
Business - Multiple users and workspaces, with three options:
- Business SaaS - Hosted alongside other accounts on Unstructured’s cloud infrastructure.
- Dedicated instance - Hosted within a virtual private cloud (VPC) running inside Unstructured’s cloud infrastructure. Dedicated instances are isolated from all other accounts, for additional security and control.
- In-VPC - Hosted within your own VPC on your own cloud infrastructure.
- For these file types, a page is a page, slide, or image:
.pdf,.pptx, and.tiff. - For
.docxfiles that have page metadata, Unstructured calculates the number of pages based on that metadata. - For all other file types, Unstructured calculates the number of pages as the file’s size divided by 100 KB.
- For non-file data, Unstructured calculates a page as 100 KB of incoming data to be processed.
How do I get started?
Skip ahead to the quickstart.Questions? Need help?
- For general questions about Unstructured products and pricing, email Unstructured Sales at sales@unstructured.io.
- For technical support for Unstructured accounts, request support.