Documentation Index
Fetch the complete documentation index at: https://docs.unstructured.io/llms.txt
Use this file to discover all available pages before exploring further.
Partitioning extracts content from raw unstructured files and outputs that content as structured document elements.
For specific file types, such as image files and PDF files, Unstructured offers special strategies to partition them. Each of these
strategies has trade-offs for output speed, cost to output, and quality of output.
PDF files, for example, vary in quality and complexity. In simple cases, traditional natural language processing (NLP) extraction techniques might
be enough to extract all the text out of a document. In other cases, advanced image-to-text models are required
to process a PDF file. Some of these strategies implement rule-based workflows, which can be faster and cheaper, because they always
extract in the same way, but you might sometimes get lower-quality resolution. Other strategies implement
model-based workflows, which can be slower and costlier because they require a model that performs inference, but you can get higher-quality resolution.
When you choose a partitioning strategy for your files, you should be mindful of these speed, cost, and quality trade-offs.
For example, the Fast strategy can be about 100 times faster than leading image-to-text models.
To choose one of these strategies, select one of the following four Partition Strategy options in the Partitioner node of a workflow.
You can change a workflow’s preconfigured strategy only through Custom workflow settings.
- VLM: For the highest-quality transformation of these file types:
.bmp,.gif,.heic,.jpeg,.jpg,.pdf,.png,.tiff, and.webp. - High Res: For all other supported file types, and for the generation of bounding box coordinates.
- Fast: For text-only documents.
.pdf files, the Auto partitioning strategy routes these files’ pages
on a page-by-page basis, as follows:
- A page is routed to Fast when it contains only embedded text and no images or tables are detected.
- All other kinds of pages are routed to VLM or High Res, depending on the complexity of a page’s content. Unstructured constantly optimizes its proprietary algorithm for routing to VLM or High Res in these cases.
Images and tables in PDF files
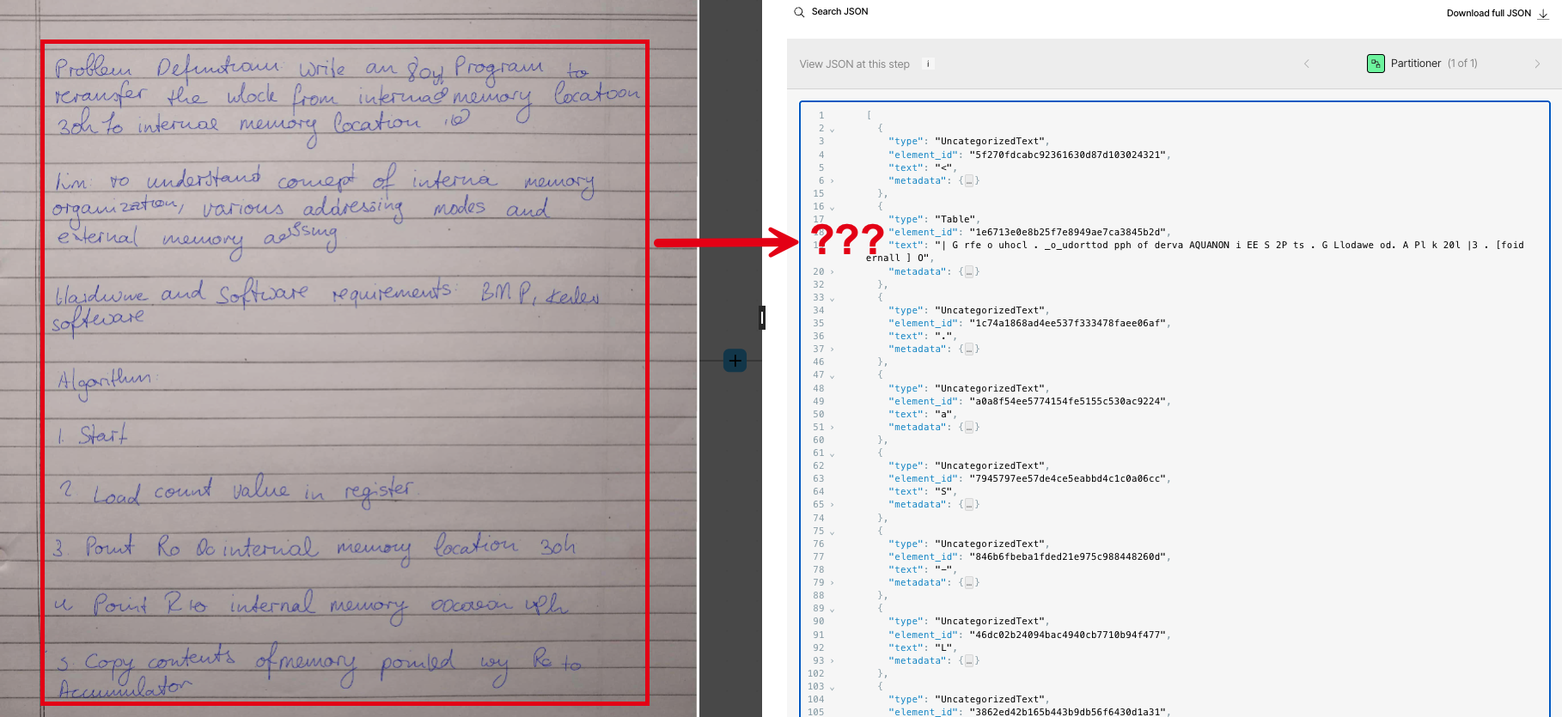
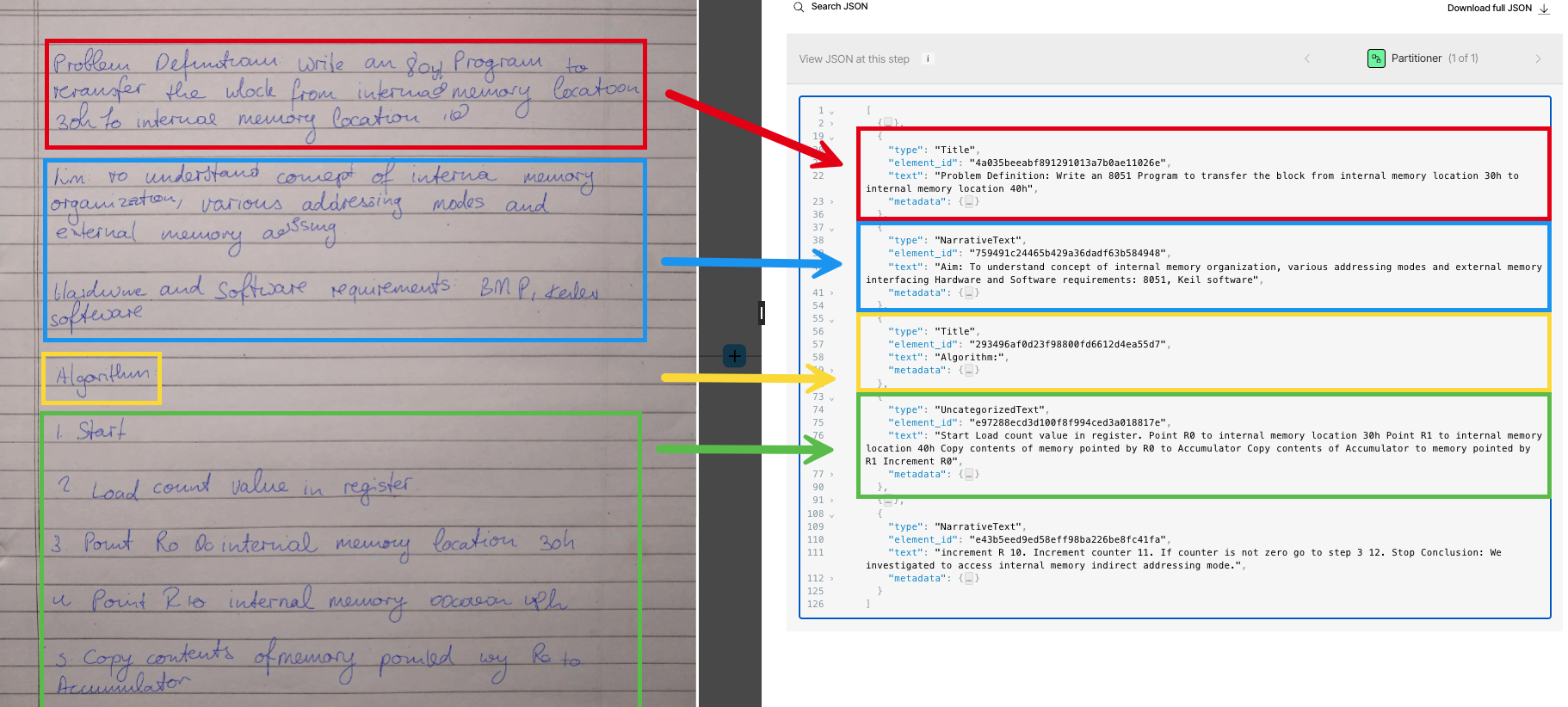
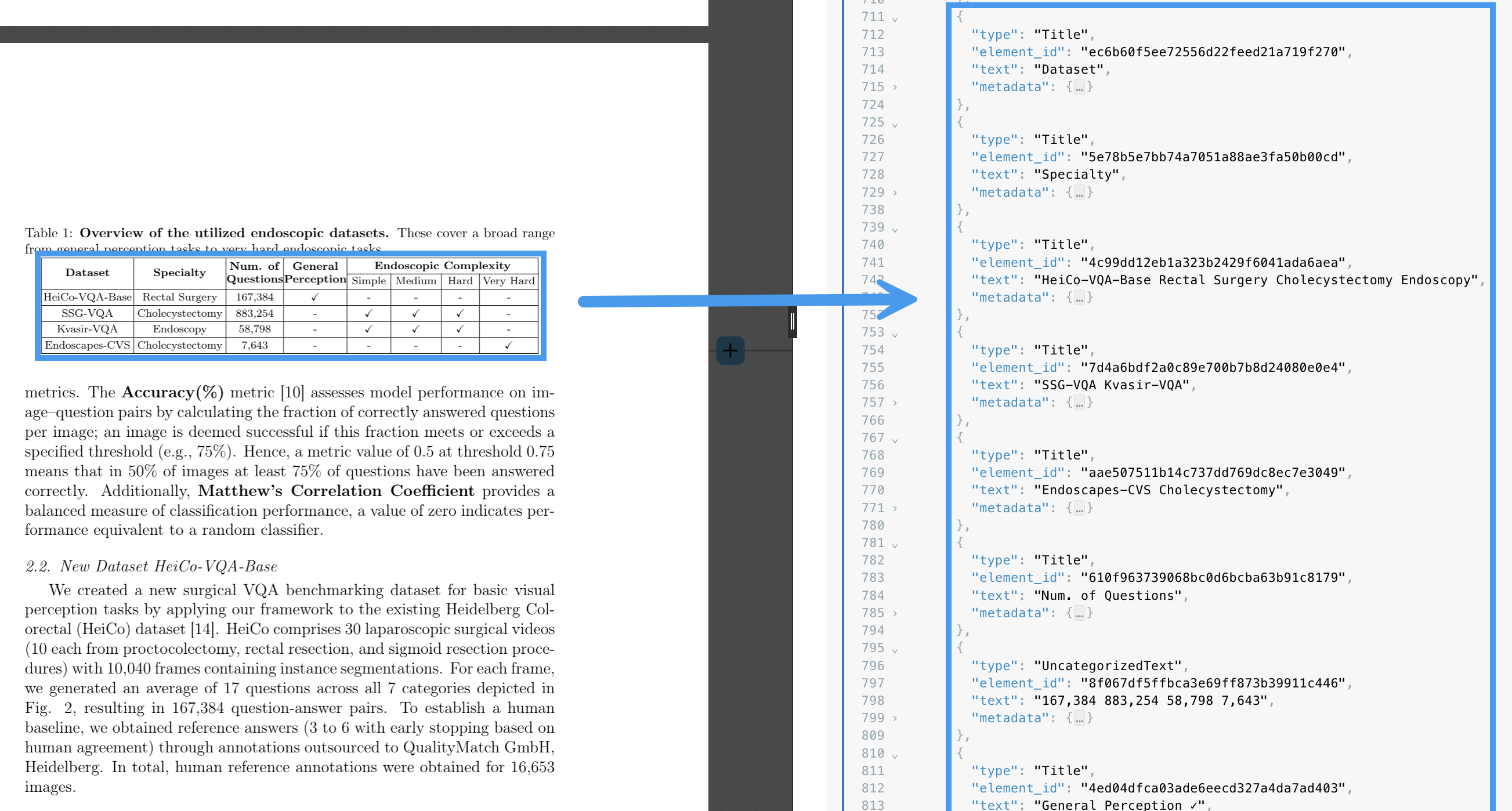
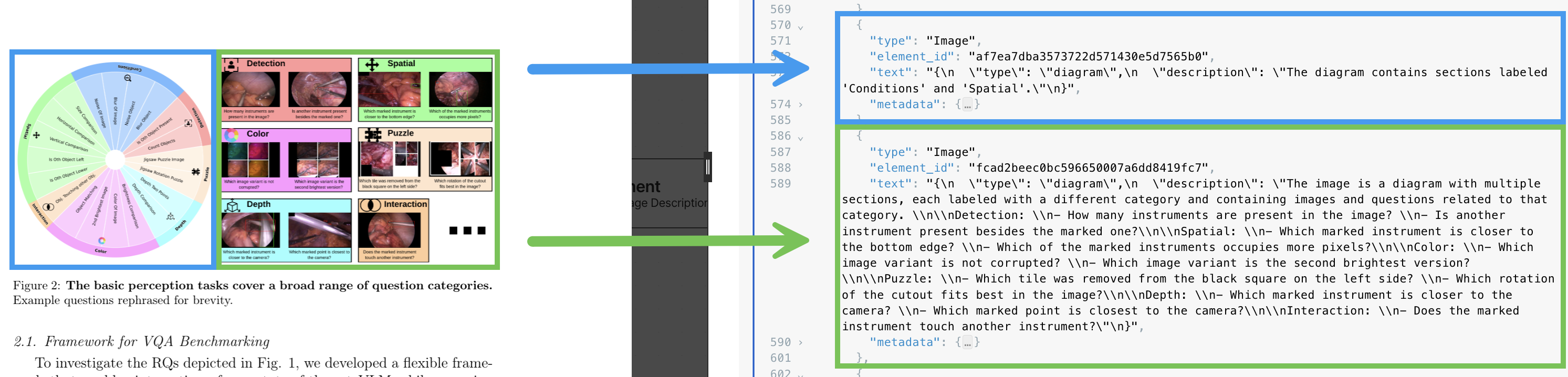
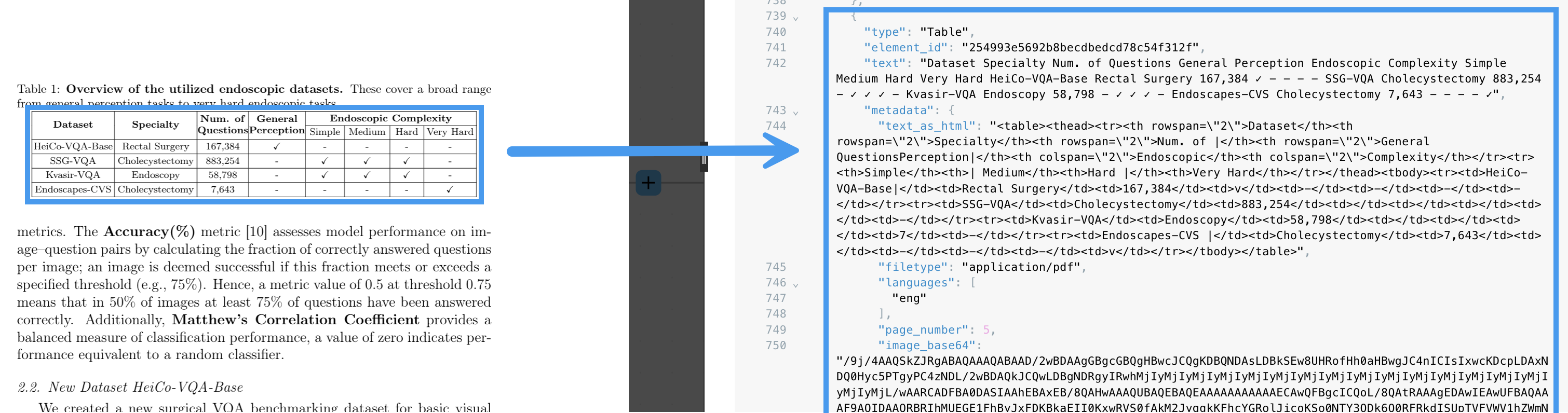
The differences between the various partitioning strategies can be more clearly demonstrated by the ways each of these strategies handle images and tables within PDF files. For example, the Fast partitioning strategy skips processing images altogether in PDF files:



Handwriting and multilanguage characters in PDF files
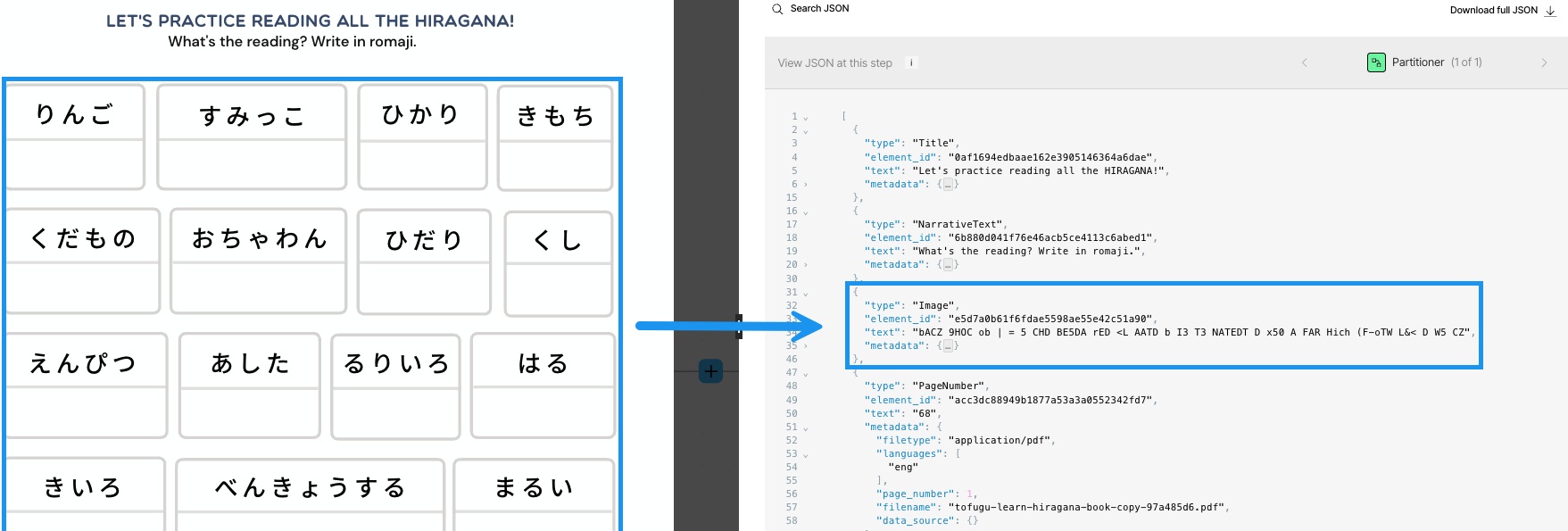
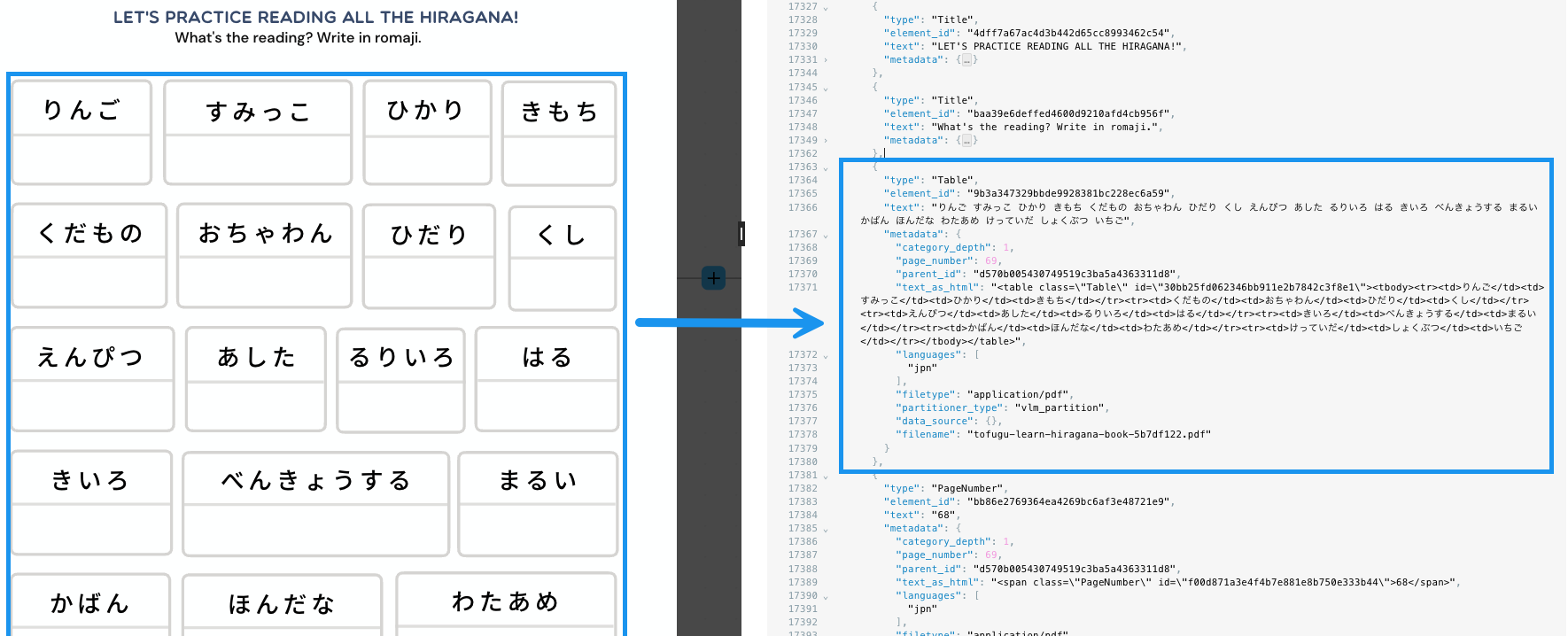
The differences between the various partitioning strategies can be more clearly demonstrated by the ways each of these strategies handle handwriting and multilanguage characters within PDF files. For example, the Fast partitioning strategy skips processing handwriting altogether in PDF files. The Fast strategy processes multilanguage characters in PDF files with limited output, depending on the language. In the following example, Japanese hiragana characters are processed as text, but the output can be very difficult to work with: