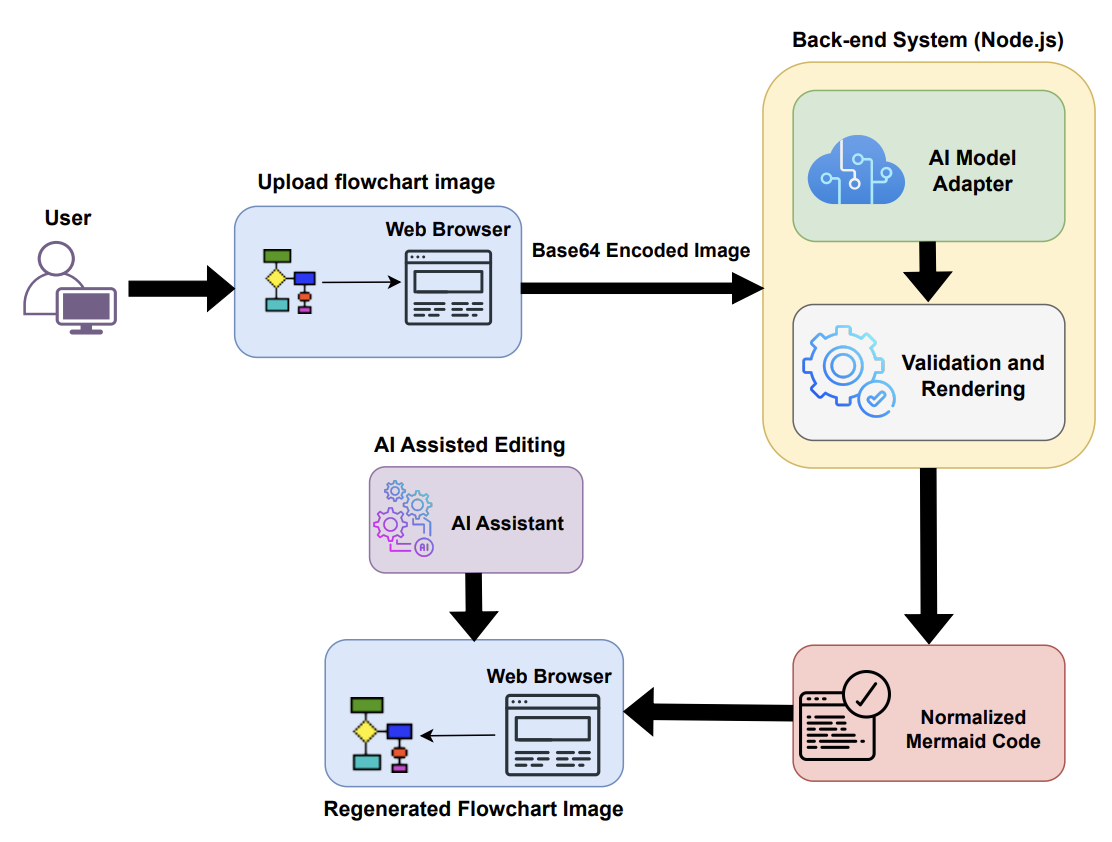
After partitioning, you can have Unstructured generate text-based summaries of detected images.
This summarization is done by using models offered through various model providers.
Here is an example of the output of a detected image using GPT-4o. Note specifically the
text field that is added.
In this text field, type indicates the kind of image that was detected (in this case, a diagram), and description is a summary of the image.
Line breaks have been inserted here for readability. The output will not contain these line breaks.
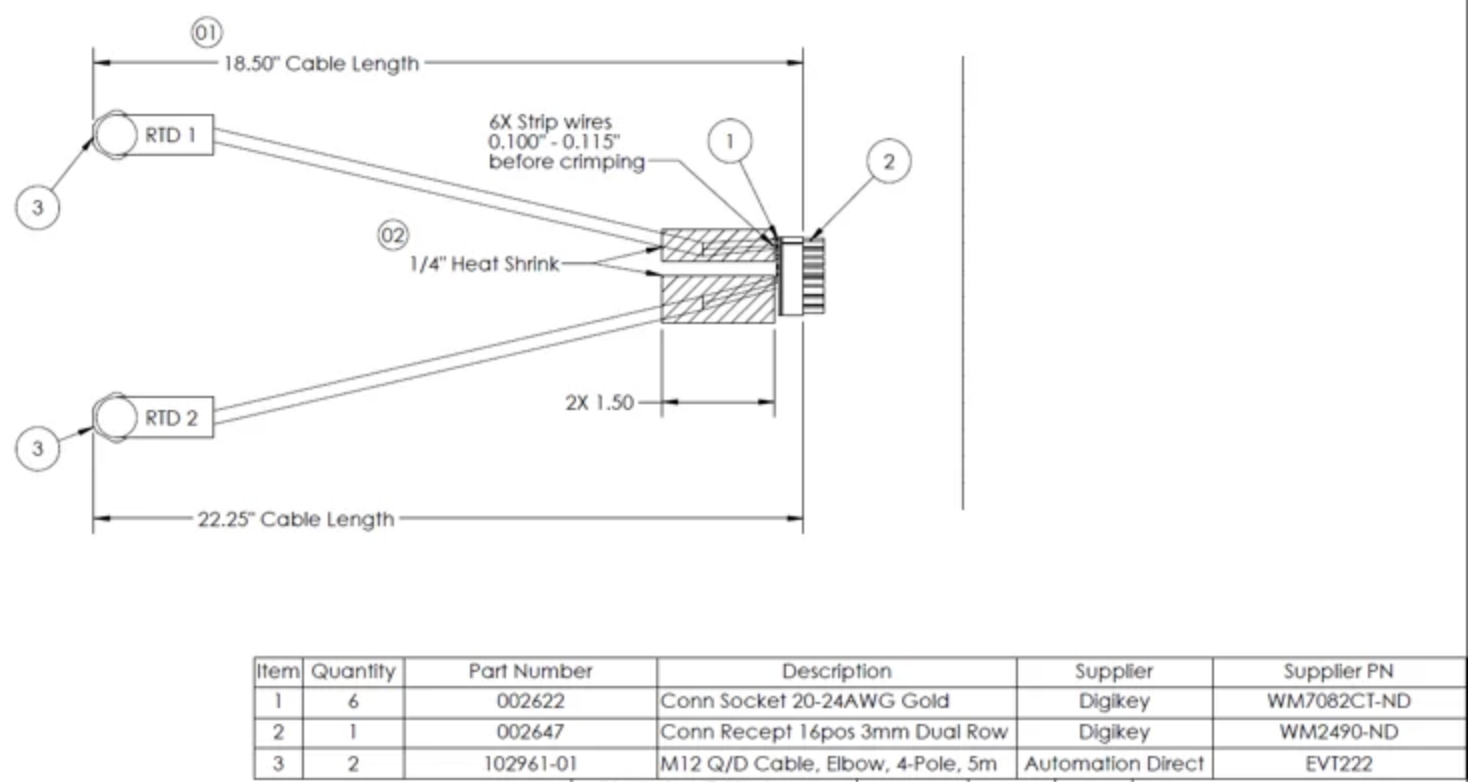
text field will contain a type of technical drawing; description with texts containing text strings found in the drawing,
tables containing HTML representations of tables found in the drawing, and a description containing a summary of the drawing.
Here is an example. Line breaks have been inserted here for readability. The output will not contain these line breaks.
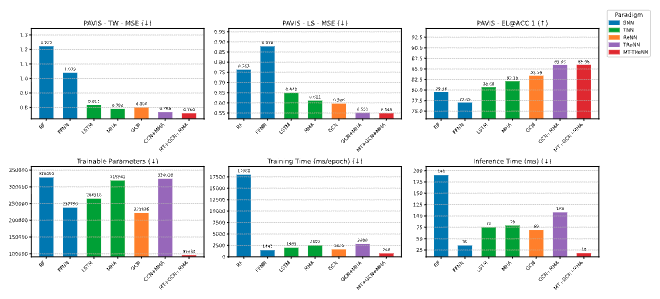
text field will contain a type of graph; description containing a summary of the graph,
data containing numerical values that can be used to regenerate the graph, and texts containing
the text strings found in the graph.
Here is an example. Line breaks have been inserted here for readability. The output will not contain these line breaks.
The
image_base64 field is generated only for documents or PDF pages that are partitioned by using the High Res strategy. This field is not generated for
documents or PDF pages that are partitioned by using the Fast or VLM strategy.- Each
Imageelement is replaced by aCompositeElementelement. - This
CompositeElementelement will contain the image’s summary description as part of the element’stextfield. - This
CompositeElementelement will not contain animage_base64field.



text field’s contents.
Generate image descriptions
To have Unstructured generate image descriptions, do the following:- For Unstructured Pipelines users, add an Enrichment node of type NER to an Unstructured custom workflow.
- For Unstructured API users, add an Image Description task. You add this task
as either as an object in a
workflow_nodesarray (for curl) or as aWorkflowNodein aWorkflowNodescollection (for Python). This object or collection applies whenever you create a workflow, update a workflow, or create a workflow job that processes local files.