Batch process all your records to store structured outputs in an S3 bucket. The requirements are as follows. The following video shows how to fulfill the minimum set of Amazon S3 requirements:Documentation Index
Fetch the complete documentation index at: https://docs.unstructured.io/llms.txt
Use this file to discover all available pages before exploring further.
The preceding video does not show how to create an AWS account; enable anonymous access to the bucket (which is supported but
not recommended); or generate AWS STS temporary access credentials if required by your organization’s security
requirements. For more information about requirements, see the following:
-
An AWS account. Create an AWS account.
-
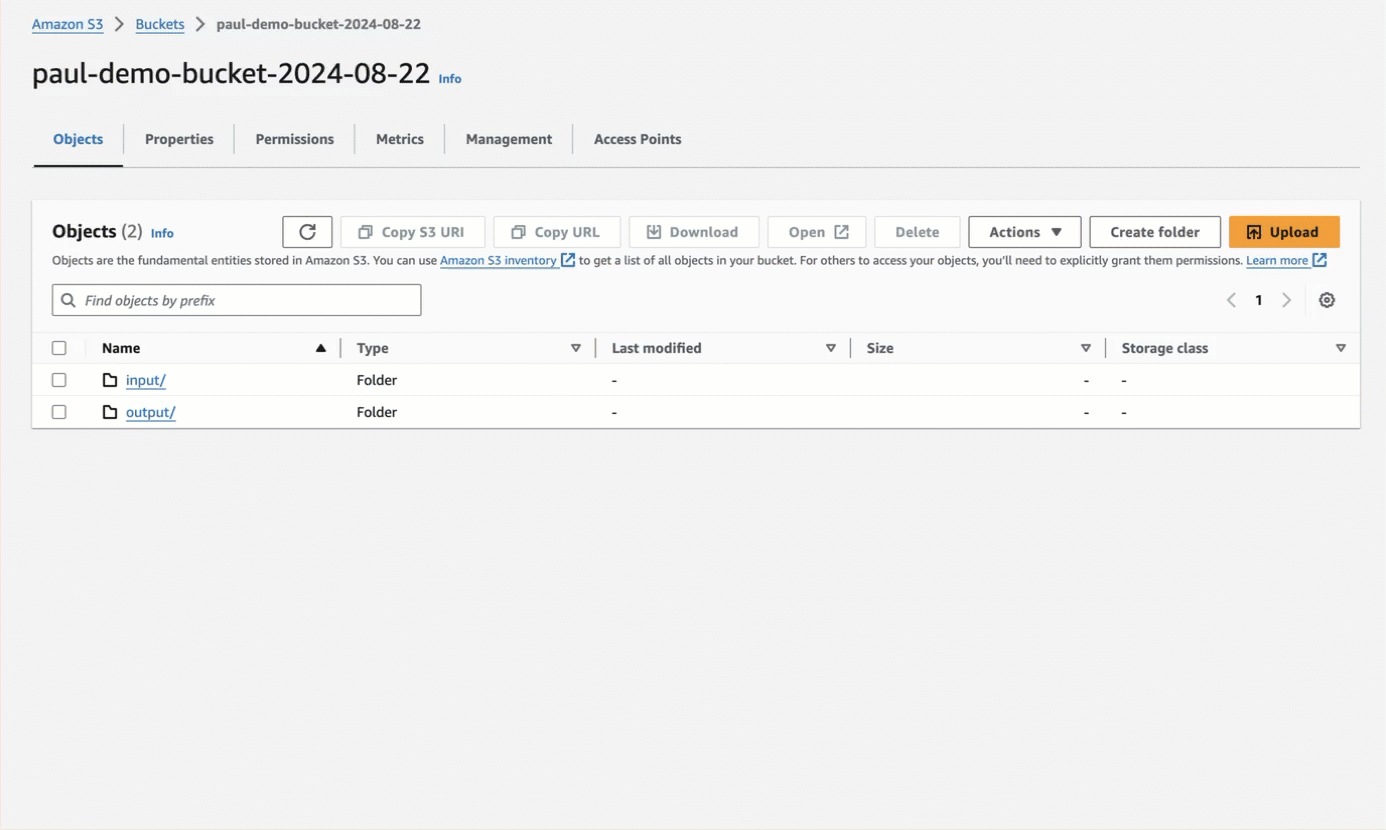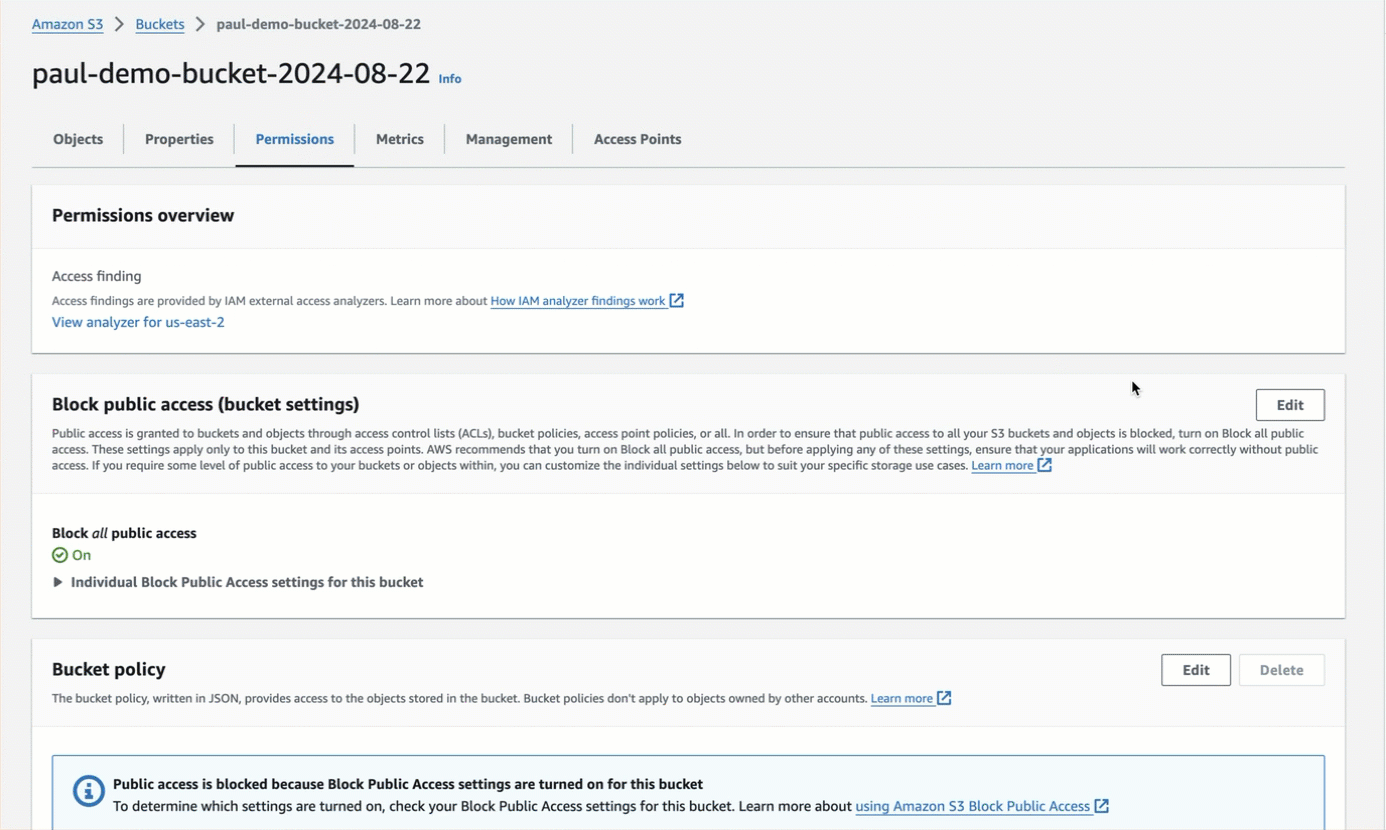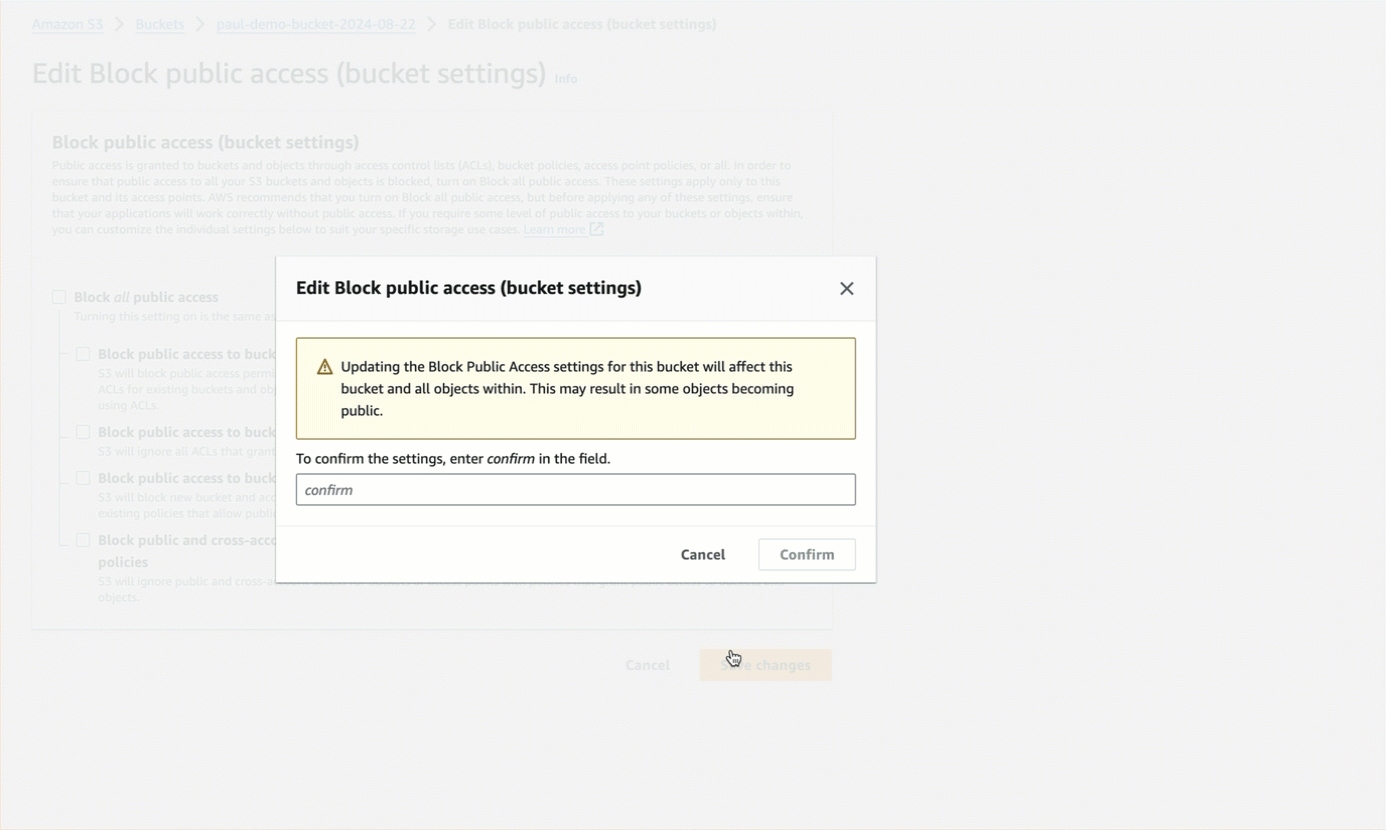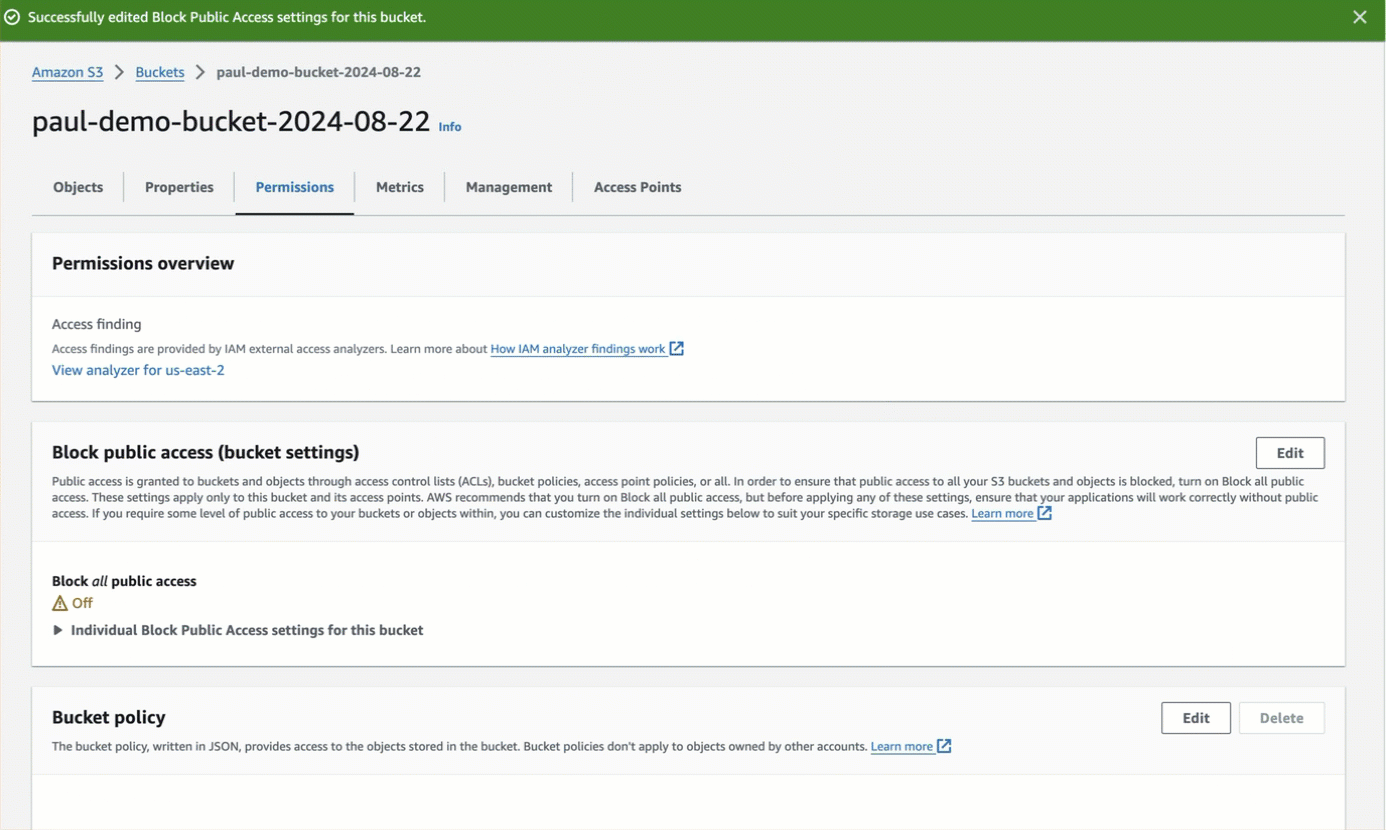
An S3 bucket. You can create an S3 bucket by using the S3 console, following the steps in the S3 documentation or in the following video.
Additional approaches that use AWS CloudFormation or the AWS CLI are in the how-to sections later on this page.
-
Anonymous access to the bucket is supported but not recommended. (Use authenticated bucket read or write access or both instead.) To enable anonymous access, follow the steps
in the S3 documentation or in the following animation.
-
For authenticated bucket read or write access or both, which is recommended over anonymous access, you should first
block all public access to the bucket.
After blocking all public access to the bucket, for read access, the authenticated AWS IAM user must have at minimum the permissions of
s3:ListBucketands3:GetObjectfor that bucket. For write access, the authenticated AWS IAM user must have at minimum the permission ofs3:PutObjectfor that bucket. Permissions can be granted in one of the following ways:-
Attach the appropriate bucket policy to the bucket. See the policy examples later on this page, and learn about bucket policies for S3. These permissions remain in effect until the bucket policy is removed from the bucket.
To apply a bucket policy by using the S3 console, follow the steps in the S3 documentation or in the following video.
Additional approaches that use AWS CloudFormation or the AWS CLI are in the how-to sections later on this page.
-
Have the IAM user temporarily assume an IAM role that contains the appropriate user policy. See the policy examples later on this page, and learn about user policies for S3. These permission remain in effect until the assumed role’s time period expires.
Learn how to use the IAM console to create a policy,
create a role that references this policy, and then
have the user temporarily assume the role by using the AWS CLI or an AWS SDK, which produces
a temporary AWS access key (
AccessKeyId), AWS secret access key (SecretAccessKey), and AWS STS session token (SessionToken).
-
Attach the appropriate bucket policy to the bucket. See the policy examples later on this page, and learn about bucket policies for S3. These permissions remain in effect until the bucket policy is removed from the bucket.
To apply a bucket policy by using the S3 console, follow the steps in the S3 documentation or in the following video.
Additional approaches that use AWS CloudFormation or the AWS CLI are in the how-to sections later on this page.
-
If you used a bucket policy intead of having the IAM user temporarily assume an IAM role for authenticated bucket access, you must provide a long-term AWS access key and secret access key for the authenticated AWS IAM user in the account.
Create an AWS access key and secret access key by following the steps in the IAM documentation or in the following video.
-
If the target files are in the root of the bucket, you will need the path to the bucket, formatted as
protocol://bucket/(for example,s3://my-bucket/). If the target files are in a folder, the path to the target folder in the S3 bucket, formatted asprotocol://bucket/path/to/folder/(for example,s3://my-bucket/my-folder/). - If the target files are in a folder, and authenticated bucket access is enabled, make sure the authenticated AWS IAM user has authenticated access to the folder as well. See examples of authenticated folder access.
CLI, Python
-
AWS_S3_URL- The path to the S3 bucket or folder, formatted ass3://my-bucket/(if the files are in the bucket’s root) ors3://my-bucket/my-folder/. -
If the bucket does not have anonymous access enabled, provide the AWS credentials:
AWS_ACCESS_KEY_ID- The AWS access key ID for the authenticated AWS IAM user, represented by--key(CLI) orkey(Python).AWS_SECRET_ACCESS_KEY- The corresponding AWS secret access key, represented by--secret(CLI) orsecret(Python).AWS_STS_TOKEN- If required, the AWS STS session token for temporary access, represented by--token(CLI) ortoken(Python).
-
If the bucket has anonymous access enabled for reading from the bucket, set
--anonymous(CLI) oranonymous=True(Python) instead.
Add an access policy to an existing bucket
To use the Amazon S3 console to add an access policy that allows all authenticated AWS IAM users in the corresponding AWS account to read and write to an existing S3 bucket, do the following.Your organization might have stricter bucket policy requirements. Check with your AWS account
administrator if you are unsure.
- Sign in to the AWS Management Console.
- Open the Amazon S3 Console.
- Browse to the existing bucket and open it.
- Click the Permissions tab.
- In the Bucket policy area, click Edit.
-
In the Policy text area, copy the following JSON-formatted policy.
To change the following policy to restrict it to a specific user in the AWS account, change
rootto that specific username. In this policy, replace the following:- Replace
<my-account-id>with your AWS account ID. - Replace
<my-bucket-name>in two places with the name of your bucket.
- Replace
- Click Save changes.
Create a bucket with the AWS CLI
To use the AWS CLI to create an Amazon S3 bucket that allows all authenticated AWS IAM users in the corresponding AWS account to read and write to the bucket, do the following.Your organization might have stricter bucket policy requirements. Check with your AWS account
administrator if you are unsure.
- Install the AWS CLI.
- Set up the AWS CLI.
-
Copy the following script to a file on your local machine, for example a file named
create-s3-bucket.sh. To change the following bucket policy to restrict it to a specific user in the AWS account, changerootto that specific username. In this script, replace the following:- Replace
<my-account-id>with your AWS account ID. - Replace
<my-unique-bucket-name>with the name of your bucket. - Replace
<us-east-1>with your AWS Region.
- Replace
-
Run the script, for example:
- After the bucket is created, you can delete the script file, if you want.
Create a bucket with AWS CloudFormation
To use the AWS CloudFormation console to create an Amazon S3 bucket that allows all authenticated AWS IAM users in the corresponding AWS account to read and write to the bucket, do the following.Your organization might have stricter bucket policy requirements. Check with your AWS account
administrator if you are unsure.
-
Save the following YAML to a file on your local machine, for example
create-s3-bucket.yaml. To change the following bucket policy to restrict it to a specific user in the AWS account, changerootto that specific username. - Sign in to the AWS Management Console.
- Open the AWS CloudFormation Console.
- Click Create stack > With new resources (standard).
- On the Create stack page, with Choose an existing template already selected, select Upload a template file.
- Click Choose file, and browse to and select the YAML file from your local machine.
- Click Next.
- Enter a unique Stack name and BucketName.
- Click Next two times.
- Click Submit.
- Wait until the Status changes to CREATE_COMPLETE.
- After the bucket is created, you can delete the YAML file, if you want.
Create a pipeline that uses S3 as the destination
Now call the Unstructured Ingest CLI or the Unstructured Ingest Python library. The source connector can be any of the ones supported. This example uses the local source connector. This example sends files to Unstructured for processing by default. To process files locally instead, see the instructions at the end of this page.--partition-by-api option (CLI) or partition_by_api (Python) parameter to specify where files are processed:
-
To do local file processing, omit
--partition-by-api(CLI) orpartition_by_api(Python), or explicitly specifypartition_by_api=False(Python). Local file processing does not use an Unstructured API key or API URL, so you can also omit the following, if they appear:--api-key $UNSTRUCTURED_API_KEY(CLI) orapi_key=os.getenv("UNSTRUCTURED_API_KEY")(Python)--partition-endpoint $UNSTRUCTURED_API_URL(CLI) orpartition_endpoint=os.getenv("UNSTRUCTURED_API_URL")(Python)- The environment variables
UNSTRUCTURED_API_KEYandUNSTRUCTURED_API_URL
-
To send files to the legacy Unstructured Partition Endpoint for processing, specify
--partition-by-api(CLI) orpartition_by_api=True(Python). Unstructured also requires an Unstructured API key and API URL, by adding the following:--api-key $UNSTRUCTURED_API_KEY(CLI) orapi_key=os.getenv("UNSTRUCTURED_API_KEY")(Python)--partition-endpoint $UNSTRUCTURED_API_URL(CLI) orpartition_endpoint=os.getenv("UNSTRUCTURED_API_URL")(Python)- The environment variables
UNSTRUCTURED_API_KEYandUNSTRUCTURED_API_URL, representing your API key and API URL, respectively.
You must specify the API URL only if you are not using the default API URL for Unstructured Ingest, which applies to Let’s Go, Pay-As-You-Go, and Business SaaS accounts.The default API URL for Unstructured Ingest ishttps://api.unstructuredapp.io/general/v0/general, which is the API URL for the legacy Unstructured Partition Endpoint. However, you should always use the URL that was provided to you when your Unstructured account was created. If you do not have this URL, email Unstructured Support at support@unstructured.io.If you do not have an API key, get one now.If you are using a Business account, the process for generating Unstructured API keys, and the Unstructured API URL that you use, are different. For instructions, see your Unstructured account administrator, or email Unstructured Support at support@unstructured.io.