Prerequisites
- An IBM Cloud account or DataStax account.
-
An Astra DB database in the DataStax account. To create a database:
a. After you sign in to DataStax, click Create database.
b. Click the Serverless (vector) tile, if it is not already selected.
c. For Database name, enter some unique name for the database.
d. Select a Provider and a Region, and then click Create database.
Learn more. -
An application token for the database. To create an application token:
a. After you sign in to DataStax, in the list of databases, click the name of the target database.
b. On the Overview tab, under Database Details, in the Application Tokens tile, click Generate Token.
c. Enter some Token description and select and Expiration time period, and then click Generate token.
d. Save the application token that is displayed to a secure location, and then click Close.
Learn more. -
A keyspace in the database. To create a keyspace:
a. After you sign in to DataStax, in the list of databases, click the name of the target database.
b. On the Data Explorer tab, in the Keyspace list, select Create keyspace.
c. Enter some Keyspace name, and then click Add keyspace.
Learn more. -
A collection in the keyspace.
For the Unstructured Pipelines and Unstructured API:
-
An existing collection is not required. At runtime, the collection behavior is as follows:
- If an existing collection name is specified, and Unstructured generates embeddings, but the number of dimensions that are generated does not match the existing collection’s embedding settings, the run will fail. You must change your Unstructured embedding settings or your existing collection’s embedding settings to match, and try the run again.
- If a collection name is not specified, Unstructured creates a new collection in your keyspace. If Unstructured generates embeddings,
the new collection’s name will be
u<short-workflow-id>_<short-embedding-model-name>_<number-of-dimensions>. If Unstructured does not generate embeddings, the new collection’s name will beu<short-workflow-id.
- For the source connector only, an existing collection is required.
-
For the destination connector only, an existing collection is not required. At runtime, the collection behavior is as follows:
- If an existing collection name is specified, and Unstructured generates embeddings, but the number of dimensions that are generated does not match the existing collection’s embedding settings, the run will fail. You must change your Unstructured embedding settings or your existing collection’s embedding settings to match, and try the run again.
- If a collection name is not specified, Unstructured creates a new collection in your keyspace. The new collection’s name will be
unstructuredautocreated.
b. On the Data Explorer tab, in the Keyspace list, select the name of the target keyspace.
c. In the Collections list, select Create collection.
d. Enter some Collection name.
e. Turn on Vector-enabled collection, if it is not already turned on.
f. Choose a mode for Embedding generation method. See Astra DB generated embeddings.
g. If you chose Bring my own, enter the number of dimensions for the embedding model that you plan to use.
h. For Similarity metric, select Cosine.
i. Click Create collection.
Learn more. -
An existing collection is not required. At runtime, the collection behavior is as follows:
- Sign up for an OpenAI account, and get your OpenAI API key.
- Sign up for a free Langflow account.
-
Get your Unstructured account and Unstructured API key:
-
If you do not already have an Unstructured account, sign up for free.
After you sign up, you are automatically signed in to your new Unstructured Let’s Go account, at https://platform.unstructured.io.
To sign up for a Business account instead, contact Unstructured Sales, or learn more.
-
If you have an Unstructured Let’s Go, Pay-As-You-Go, or Business SaaS account and are not already signed in, sign in to your account at https://platform.unstructured.io.
For other types of Business accounts, see your Unstructured account administrator for sign-in instructions, or request support.
-
Get your Unstructured API key:
a. After you sign in to your Unstructured Let’s Go, Pay-As-You-Go, or Business account, click API Keys on the sidebar.
b. Click Generate API Key.For a Business account, before you click API Keys, make sure you have selected the organizational workspace you want to create an API key for. Each API key works with one and only one organizational workspace. Learn more.
c. Follow the on-screen instructions to finish generating the key.
d. Click the Copy icon next to your new key to add the key to your system’s clipboard. If you lose this key, simply return and click the Copy icon again.
-
If you do not already have an Unstructured account, sign up for free.
After you sign up, you are automatically signed in to your new Unstructured Let’s Go account, at https://platform.unstructured.io.
Create and run the demonstration project
1
Create the Langflow project
- Sign in to your Langflow dashboard.
- From your dashboard, click New Project.
- Click Blank Flow.
2
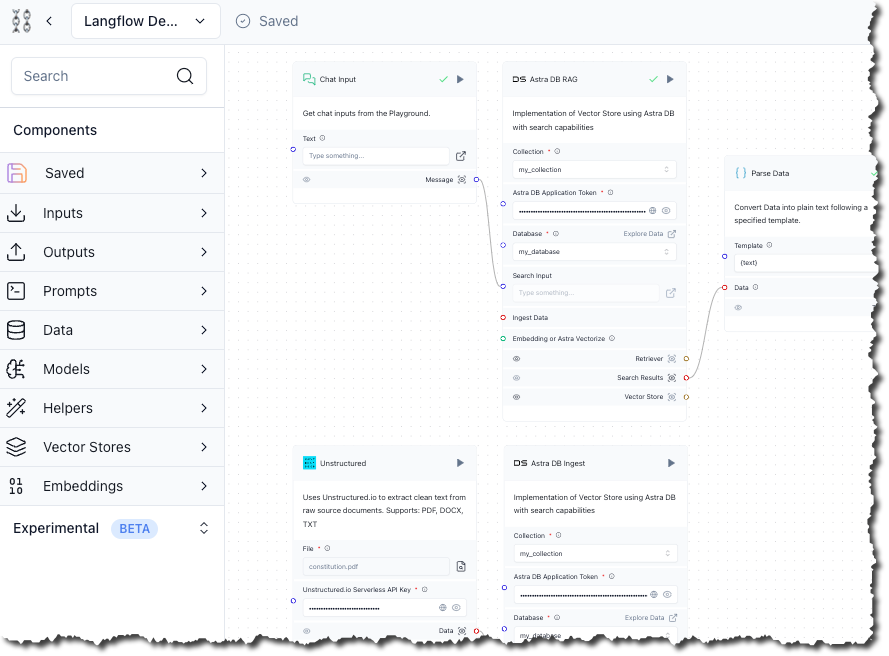
Add the Unstructured component
In this step, you add a component that instructs the legacy Unstructured Partition Endpoint to process a local file that you specify.
- On the sidebar, expand Experimental (Beta), and then expand Loaders.
- Drag the Unstructured component onto the designer area.
-
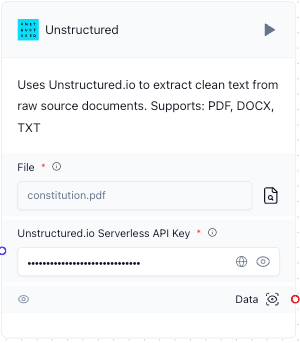
In the Unstructured component, click the box or icon next to File, and then select a local file for Unstructured to process.
This component works only with the file extensions
.pdf,.docx, and.txt. Although you can use any local file with one of these extensions, this demonstration uses the text of the United States Constitution in PDF format, saved to your local development machine. -
For Unstructured.io Serverless API Key, enter your Unstructured API key value.
-
Wait until Saved appears in the top navigation bar.
3
Add the OpenAI Embeddings component
In this step, you add a component that generates vector embeddings for the processed data that Unstructured outputs.
- On the sidebar, expand Embeddings, and then drag the OpenAI Embeddings component onto the designer area.
-
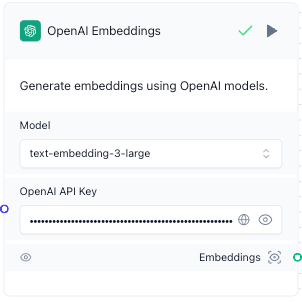
In the OpenAI Embeddings component, for Model, select
text-embedding-3-large. -
For OpenAI API Key, enter your OpenAI API key’s value.
- Wait until Saved appears in the top navigation bar.
4
Add the Astra DB components
In this step, you add two components. The first component instructs Astra DB to ingest into the specified Astra DB collection the processed data that Unstructured outputs along
with the associated generated vector embeddings. The second component instructs Astra DB to take user-supplied chat messages and perform contextual
searches over the ingested data in the specified Astra DB collection, outputting its search results.
- On the sidebar, expand Vector Stores, and then drag the Astra DB component onto the designer area.
-
Double-click the Astra DB component’s title bar, and rename the component to
Astra DB Ingest. -
Repeat these previous two actions to add a second Astra DB component, renaming it to
Astra DB RAG. - In both of these Astra DB components, in the Database list, select the name of your Astra DB database. Make sure this is the same database name in both components.
- In the Collection list in both components, select the name of the collection in the database. Make sure this is the same collection name in both components.
- In the Astra DB Application Token box in both components, enter your Astra DB application token’s value. Make sure this is the same application token value in both components.
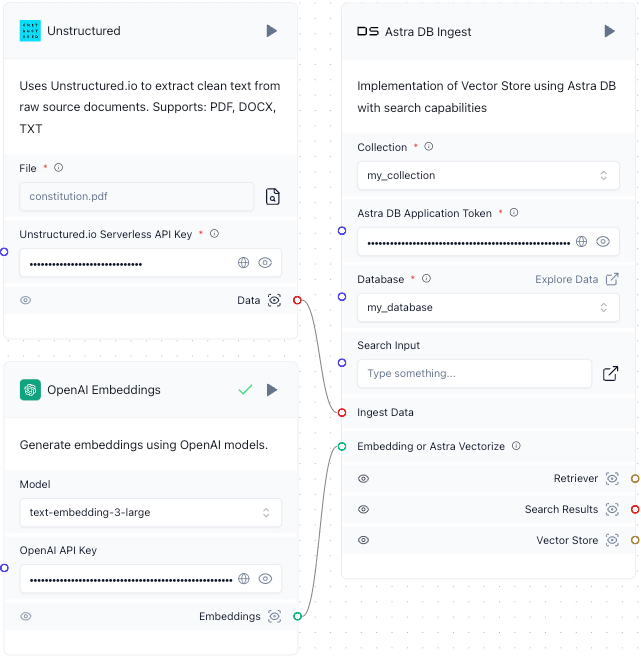
- Connect the Data output from the Unstructured component to the Ingest Data input in the Astra DB Ingest component. To make the connection, click and hold your mouse pointer inside of the circle next to Data in the Unstructured component. While holding your mouse pointer, drag it over into the circle next to Ingest Data in the Astra DB Ingest component. Then release your mouse pointer. A line appears between these two circles.
-
Connect the Embeddings output from the OpenAI Embeddings component to the Embedding or Astra Vectorize input in the Astra DB Ingest component.
- Wait until Saved appears in the top navigation bar.
-
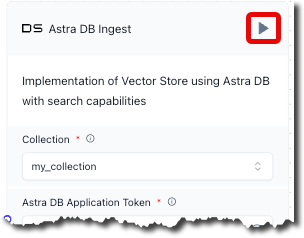
In the title bar of the Astra DB Ingest component, click the play icon. This ingests the processed data
from Unstructured and the associated generated vector embeddings into the specified Astra DB collection.
-
Wait until Building disppears from the top navigation bar, and a green check mark appears next to this play icon. This could take several minutes.
Each time you click the play icon in the Astra DB Ingest component, Unstructured reprocesses the specified local file. If this file does not change, this could result in multiple duplicate records being inserted into the specified Astra DB collection. You should only click the play icon in the Astra DB Ingest component when you want to insert new processed data into the specified Astra DB collection.
5
Add the Chat Input component
In this step, you add a component that takes user-supplied chat messages and sends them as input to Astra DB for contextual searching.
- On the sidebar, expand Inputs, and then drag the Chat Input component onto the designer area.
-
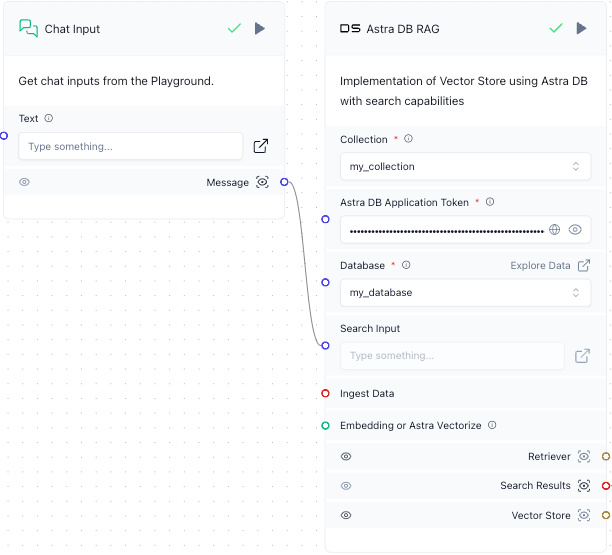
Connect the Message output from the Chat Input component to the Search Input input in the Astra DB RAG component.
- Wait until Saved appears in the top navigation bar.
6
Add the Parse Data component
In this step, you add a component that takes the Astra DB search results and converts them into plain text, suitable for inclusion in
a prompt to a text-based LLM.
- On the sidebar, expand Helpers, and then drag the Parse Data component onto the designer area.
-
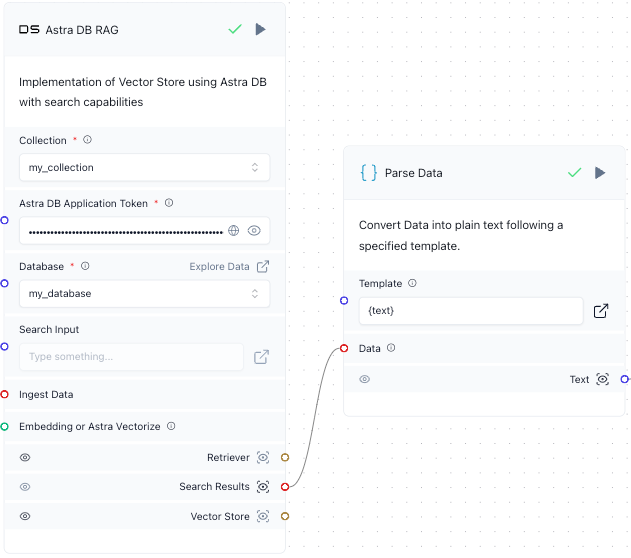
Connect the Search Results output from the Astra DB RAG component to the Data input in the Parse Data component.
- Wait until Saved appears in the top navigation bar.
7
Add the Prompt component
In this step, you add a component that builds a prompt and then sends it to a text-based LLM.
- On the sidebar, expand Prompts, and then drag the Prompt component onto the designer area.
- In the Prompt component, next to Template, click the box or arrow icon.
-
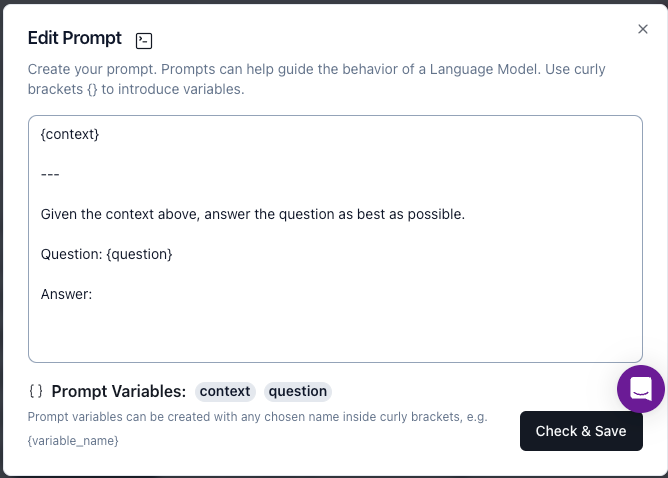
In the Edit Prompt window, enter the following prompt:
-
Click Check & Save.
-
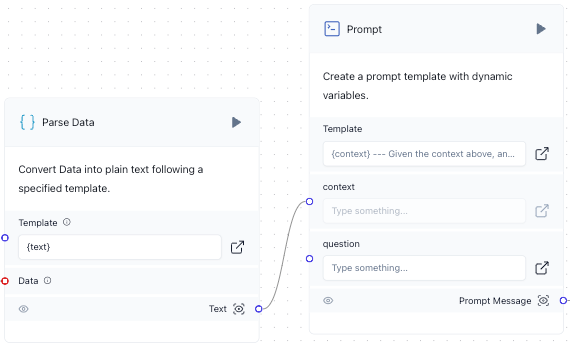
Connect the Text output from the Parse Data component to the context input in the Prompt component.
-
Connect the Message output from the Chat Input component to the question input in the Prompt component.
You will now have two connections from the Message output in the Chat Input component:
- One connection was already made to the Search Input input in the Astra DB RAG component.
- Another connection has just now been made to the question input in the Prompt component.
- Wait until Saved appears in the top navigation bar.
8
Add the OpenAI component
In this step, you create a component that sends a prompt to a text-based LLM and outputs the LLM’s response.
- On the sidebar, expand Models, and then drag the OpenAI component onto the designer area.
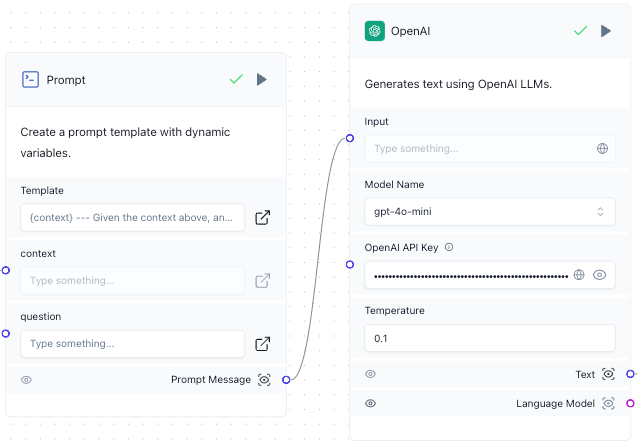
- In the Model Name list, select gpt-4o-mini.
- For OpenAI API Key, enter your OpenAI API key’s value.
-
For Temperature, enter
0.1. -
Connect the Prompt Message output from the Prompt component to the Input input in the OpenAI component.
- Wait until Saved appears in the top navigation bar.
9
Add the Chat Output component
In this step, you create a component that returns the answer to the user’s original chat message.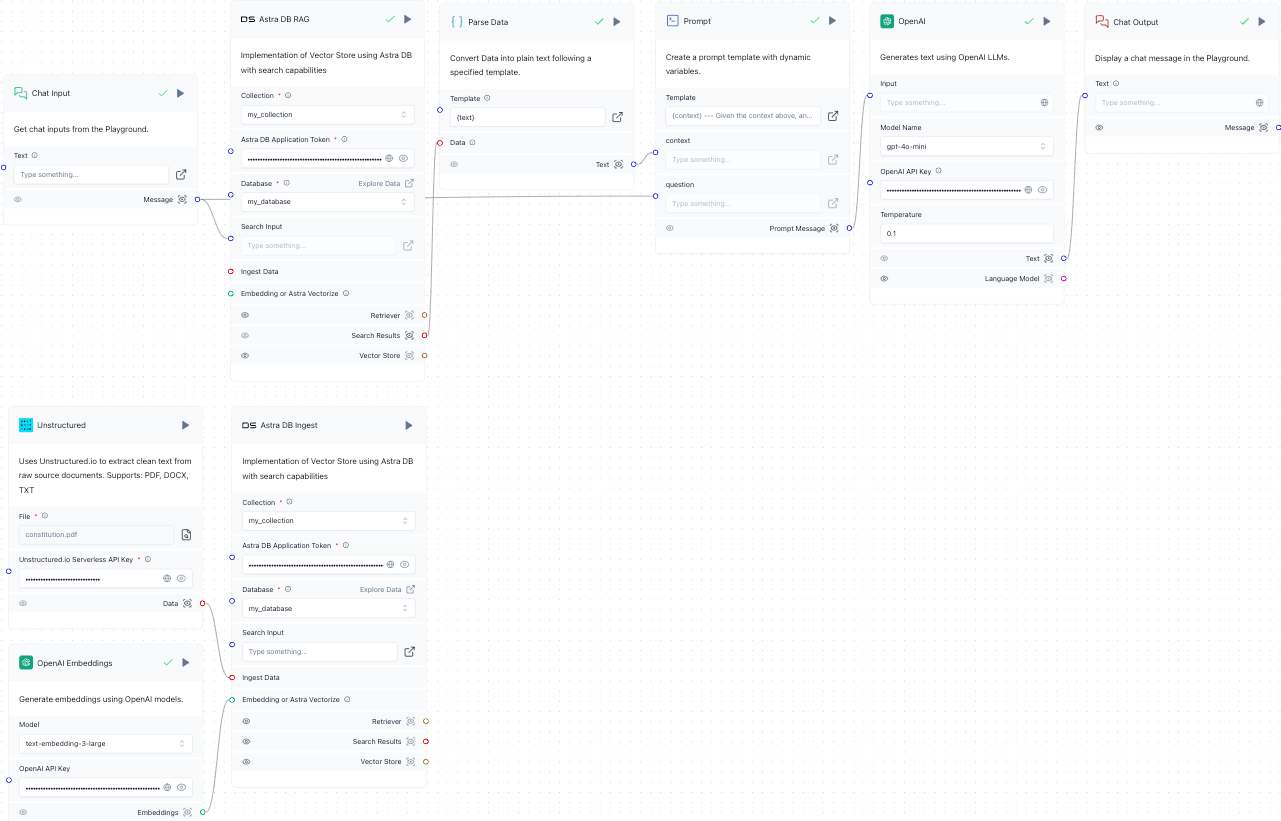
- On the sidebar, expand Outputs, and then drag the Chat Output component onto the designer area.
-
Connect the Text output from the OpenAI component to the Text input in the Chat Output component.
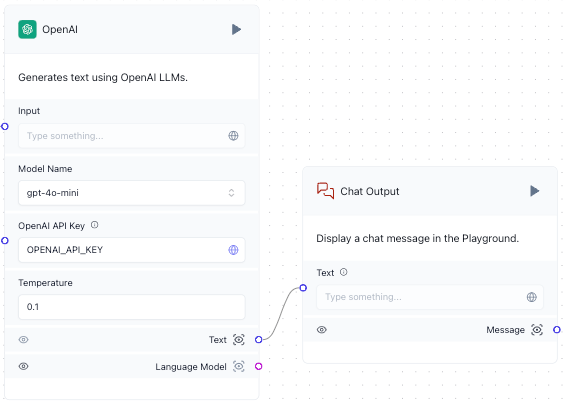
- Wait until Saved appears in the top navigation bar.
10
Run the project
-
In the designer area, click Playground.
-
Enter a question into the chat box, for example,
What rights does the fifth amendment guarantee?Then press the send button.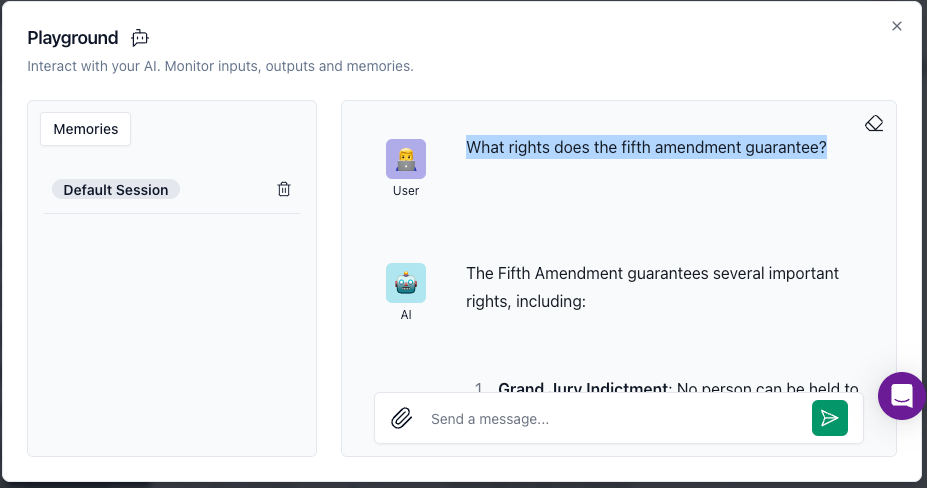
- Wait until the answer appears.
- Ask as many additional questions as you want to.
Next steps
Now that you have your pipeline set up, here are just a few ways that you could modify it to support different requirements, such as processing multiple files or using a different vector store.Process multiple files
In this demonstration, you pass to Unstructured a single local file. To pass multiple local or non-local files to Unstructured instead, you can use the Unstructured Pipelines or the Unstructured API or Unstructured Ingest outside of Langflow. To do this, you can:- Use Unstructured Pipelines to create a workflow that relies on any available source connector to connect to Astra DB. Run this workflow outside of Langflow anytime you have new documents in that source location that you want Unstructured to process and then insert the new processed data into Astra DB. Then, back in the Langflow project, use the Playground to ask additional questions, which will now include the new data when generating answers.
- Use Unstructured Ingest to create a pipeline that relies on any available source connector to connect to Astra DB. Run this pipeline outside of Langflow anytime you have new documents in that non-local source location that you want Unstructured to process and then insert the new processed data into Astra DB. Then, back in the Langflow project, use the Playground to ask additonal questions, which will now include the new data when generating answers.