When Unstructured partitions your source documents, the default output is a list of Unstructured document elements. Unstructured expresses these elements in its own format — types includeDocumentation Index
Fetch the complete documentation index at: https://docs.unstructured.io/llms.txt
Use this file to discover all available pages before exploring further.
Title, NarrativeText, UncategorizedText, Table, Image, and List.
Consider a situation where you have a stack of customer order forms in PDF format — identical layout, but different content per order. You might want to extract common fields like customer IDs, item quantities, and order totals. Normally, that would require custom logic you write yourself.
Unstructured’s structured data extractor simplifies this kind of scenario without requiring custom logic. It lets you define the target structure up front. Unstructured then extracts values in a consistent JSON format that matches your fields, ready to use in your own applications.
The diagram below shows how data flows from a patient form into JSON output, saved to cloud file storage. From there, you could run a script to insert the JSON as records into a database.

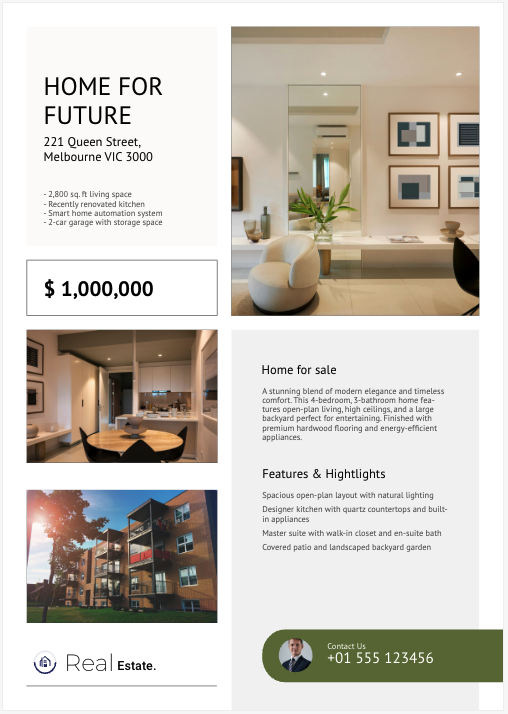
text fields contain information about the listing, such as the street address, the square footage, and one of the listing’s features. The default output leaves you parsing values out of generic text fields. With the structured data extractor, each value is captured in its own named field — structurally accessible and directly consumable by your applications without additional parsing logic.
Custom-defined output
By using the structured data extractor in your Unstructured workflows, you can have Unstructured extract the listing’s data in a custom-defined format.Elements with extracted data format
The first custom-defined output format is known as the elements with extracted data format, as follows (ellipses indicate omitted fields for brevity):DocumentData — carries your extracted fields in an extracted_data field under metadata. From the second element onward, Unstructured also outputs the document’s data as its standard document elements and metadata. The following illustrates the layout at a glance:
Extracted data only format
The second custom-defined output format is known as the extracted data only format, as follows:In the workflow editor, the Schema-Only Output toggle controls which format is used. Switch it ON to get the extracted data only format, or leave it OFF (the default) to get the elements with extracted data format.
- For step-by-step instructions in the UI, see the workflow editor procedure.
- For API users, these correspond to the output formats described in the Extract node API reference.
Limitations
The structured data extractor is not guaranteed to work with the Pinecone destination connector. This is because Pinecone has strict limits on the amount of metadata that it can manage. These limits are below the threshold of what the structured data extractor typically needs for the amount of metadata that it manages.Next steps
- To learn about the two structured data extraction methods — LLM and Regex — and compare them to decide which fits your use case, see Choose an extraction method: LLM or Regex.
- To go straight to step-by-step procedures, see Using the structured data extractor.